uProc saved time and engineering resources by using n8n to collect and wrangle data from a multi-page website.
Miquel Colomer is a self-proclaimed “IT, data, and open-source freak”. He is also the founder of uProc (and creator of the uProc node), a company that offers data solutions such as collection, cleaning, and automation.
One of his projects involved collecting and wrangling data from a multi-page website–a task he accomplished with n8n. Learn about the common challenges in web-scraping, how Miquel built a low-code workflow for this use case, and what is his advice for getting started with workflow automation.
The use case: scraping banking information
uProc creates tools that simplify data access, collect data (about persons, companies, products etc.), and use the Internet as a data source. For one project, Miquel had to create two tools for collecting banking-related data: financial data by Swift Code and Swift Code by IBAN account number.
The advantage of using the Internet as a data source is that it provides a tremendous amount of data, so Miquel could find the information they needed. However, when it came to using this information in his application, he encountered several challenges.
Challenges of web-scraping
When trying to collect data from the Internet, Miquel usually encounters three main challenges:
- The data is spread around different sources, which makes it difficult to collect and maintain.
- The data is available in different formats (e.g. HTML, RSS, CSV, XML), which makes it difficult to combine and process.
- The data is sometimes outdated, which makes it difficult to build reliable useful applications.
In the end, Miquel found the Swift codes that he needed for his application at https://www.theswiftcodes.com. In the next step, he needed to collect this data in a structured way. In the beginning, he used Python scripts making use of dedicated web-crawling libraries like Scrapy.
Though the scripts were up to the task, writing the code involved repetitive manual work and was time-consuming, as it included selecting the right tags and selectors, formatting, and processing the data in a way that could eventually be used in the end application.
In an effort to avoid manually writing extensive code, Miquel turned to workflow automation with n8n.
The low-code solution for scraping multi-page websites
Miquel built a 22-node low-code workflow that scrapes static websites with pagination. The workflow extracts data from every country page on the https://www.theswiftcodes.com/browse-by-country/ website and stores the collected information in MongoDB.
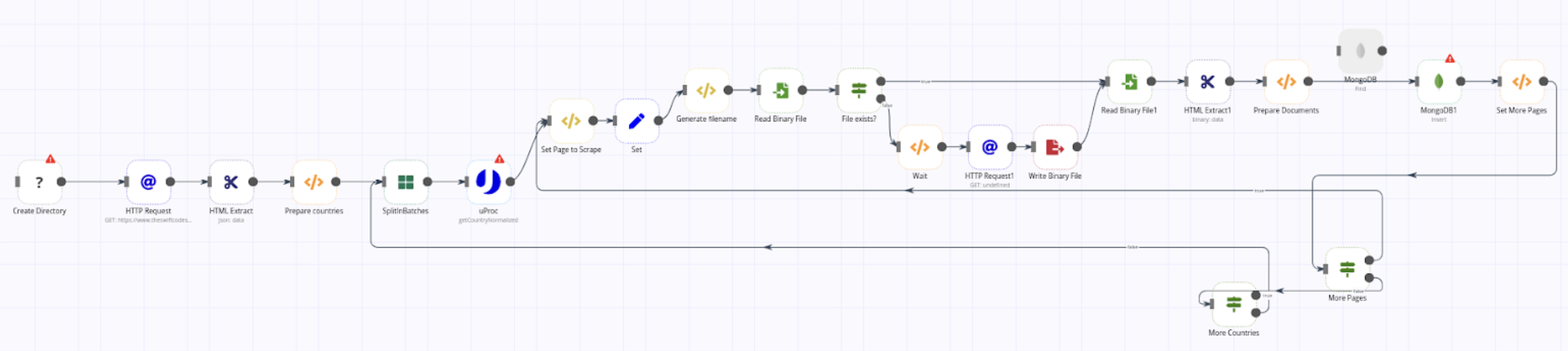
To accomplish the individual tasks involved in the web-scraping process, the workflow relies on two regular nodes (MongoDB and uProc) and ten core nodes:
- the Execute Command node (to automatically create a local cache directory before starting the web-scraping process and avoid scraping the same pages)
- the HTTP Request node (to access data from the https://www.theswiftcodes.com website)
- the HTML Extract node (to extract the desired content from the website based on their HTML tags)
- the Function and Function Item nodes (to run custom JavaScript code, for example, setting additional pages to scrape)
- the Set node (to set the necessary fields before transferring the data)
- the IF node (to filter information based on conditional logic, for example, checking whether a Swift code already exists in the database)
- the Read Binary File and Write Binary File nodes (to read and write data collected from the website)
- the Split In Batches node (to loop through the data)
With this workflow, Miquel was able to not only accomplish his project but also save precious time and resources by automating away repetitive coding.
How to get started with workflow automation
Workflow automation tools like n8n help you design powerful automations, thus increasing your productivity and reducing human errors. You can combine apps, services, and core functions to automate small common tasks, power up your workflows with a few lines of JavaScript, and even create automation-backed products.
Use no-code or low-code solutions to create MVPs or tasks quickly. I avoid coding, I only code what I need.
Miquel’s advice for anyone interested in using workflow automation is:
Use your imagination to create your side project. Think about a problem that you need to solve and try to solve it with n8n.
If you want to get in touch with Miquel Colomer, you can contact him via email, LinkedIn, or Telegram @mcolomer1975. If you are a Spanish speaker, feel free to also join the Telegram group @comunidadn8n.
Use no-code or low-code solutions to create MVPs or tasks quickly. I avoid coding, I only code what I need.
Miquel Colomer
Founder at uProc