See llms.txt for all machine-readable content.


If you have made some investments in cryptocurrency, this workflow will allow you to create an Airtable base that will update the value of your portfolio every hour. You can then track how well your investments are doing.
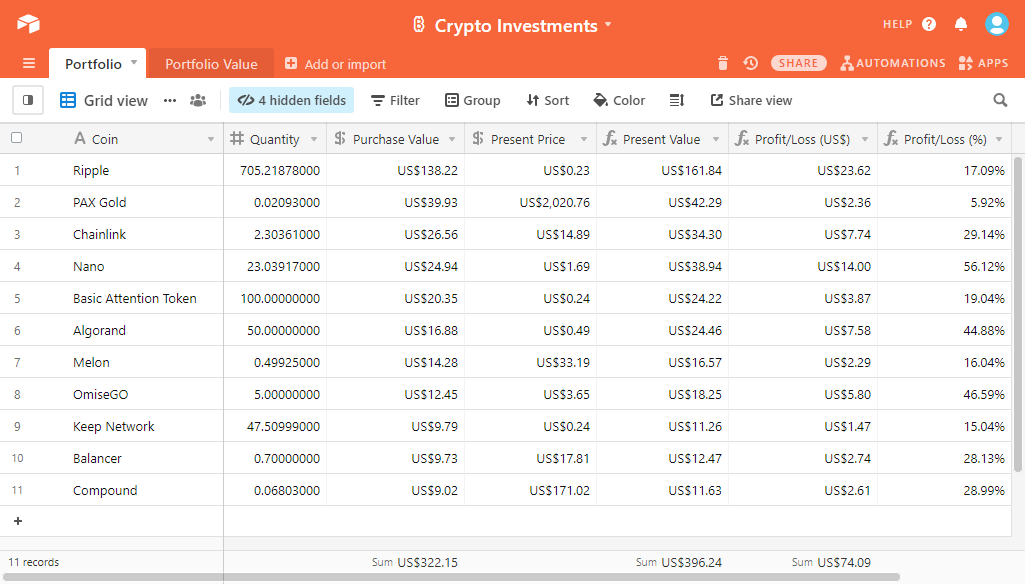
You can check out my Airtable base to see how it works or even copy my base so that you can customize this workflow for yourself.
To implement this workflow, you will need to update the Airtable nodes with your own credentials and make sure that they are pointing to your Airtable