
Objective
In industry and production sometimes machine data is available in databases. That might be sensor data like temperature or pressure or just binary information.
In this sample flow reads machine data and sends an alert to your SIGNL4 team when the machine is down. When the machine is up again the alert in SIGNL4 will get closed automatically.
Setup
We simulate the machine data using a Notion table.
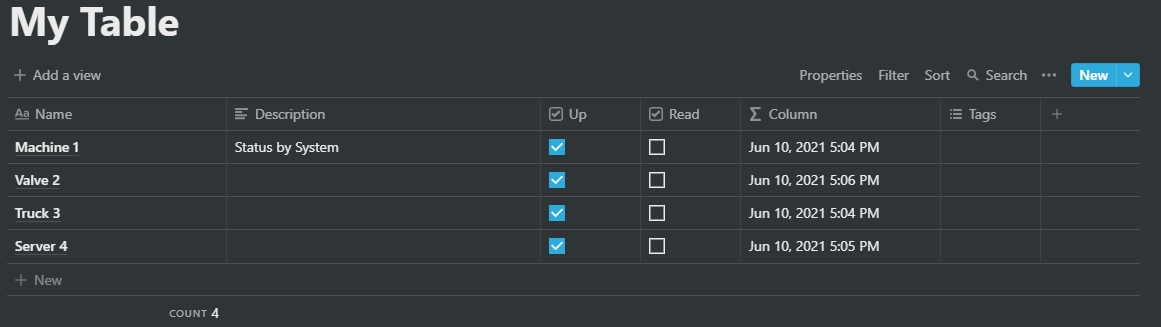
When we un-check the Up box we simulate a machine-down event. In certain intervals n8n checks the database for down items. If such an item has been found an alert is send using SIGNL4 and the item in Notion is updates (in order not to read it again).
Status updates from SIGNL4 (acknowledgement, close, annotation, escalation, etc.) are received via webhook and we update the Notion item accordingly.
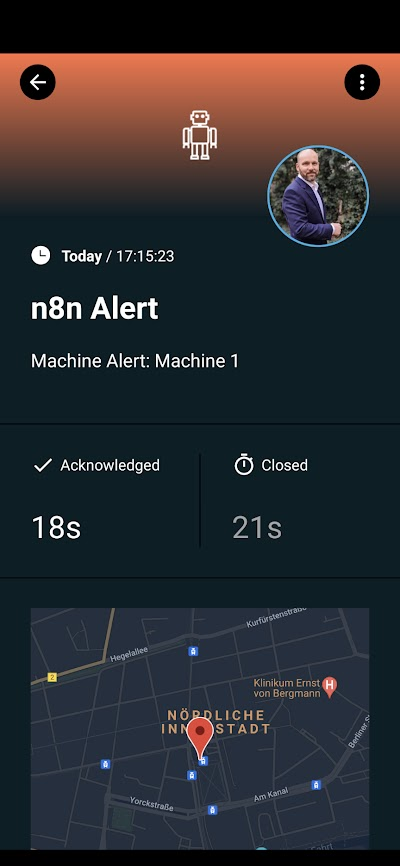
This is how the alert looks like in the SIGNL4 app.
The flow can be easily adapted to other database monitoring scenarios.