See llms.txt for all machine-readable content.


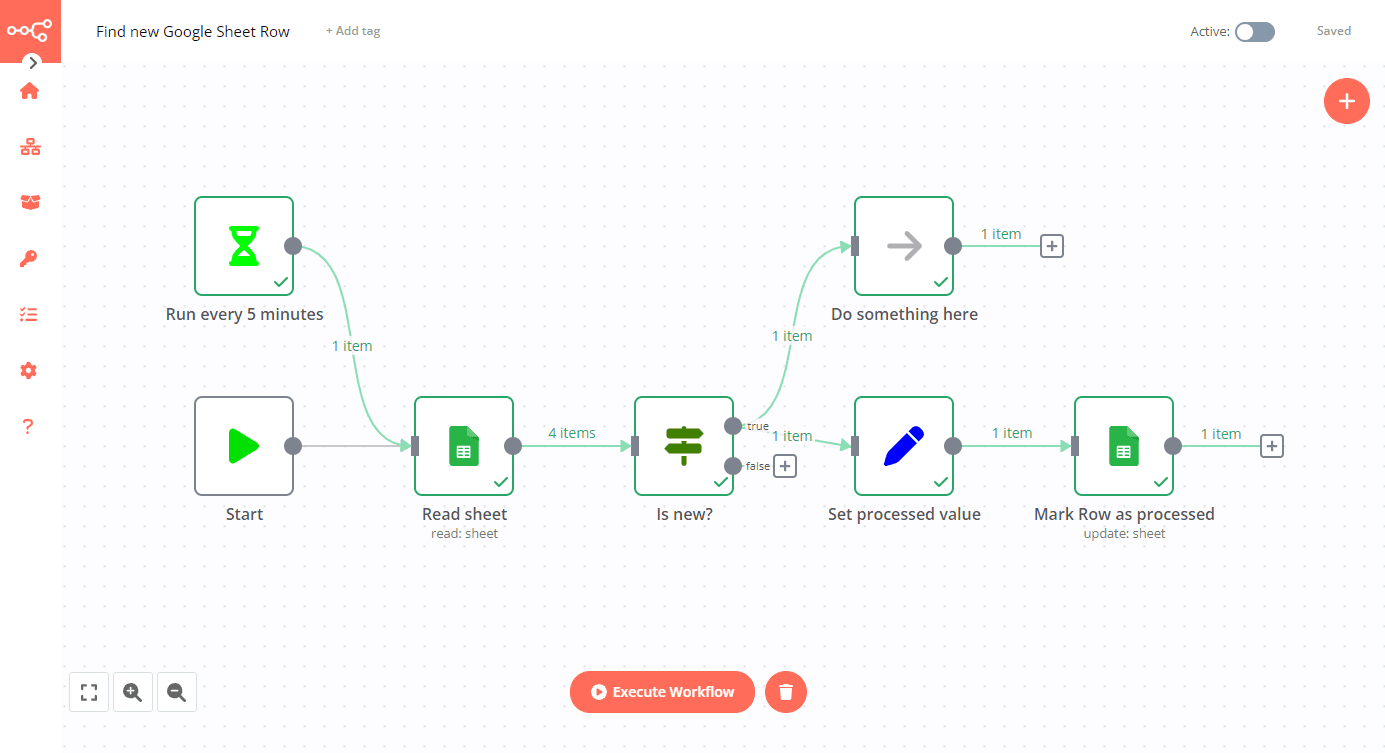
This workflow identifies new rows in Google Sheets using a separate column keeping track of already processed rows.
For this approach to work, the sheet needs to meet two requirements:
- A unique identifier for each row is required
- A column used to differentiate new/processed rows is present
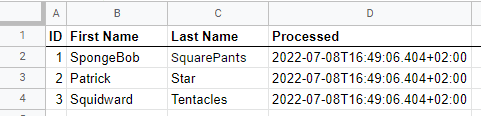
Our example sheet looks like this:
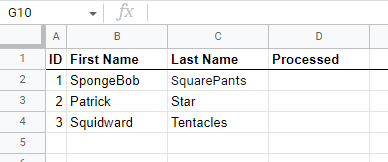
So the row identifier is named ID, the new/processed column is called Processed. Update the workflow accordingly if your columns have different names.
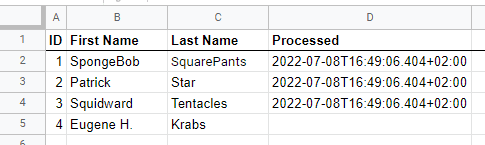
Now if the workflow runs, it discovers all three rows as new. After processing them, it will add a timestamp to the Processed column:
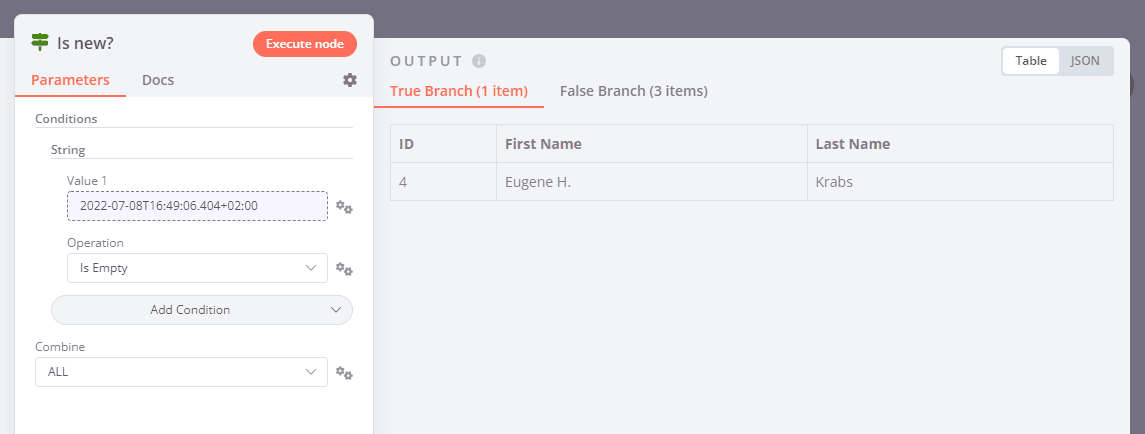
The next time the workflow is executed it will skip the existing rows and only process newly added data: