

This workflow builds a valid RSS feed (which is an XML feed under the hood) for ARD Audiothek podcasts. This allows you to subscribe to such podcasts using your favourite podcatcher without using the ARD Audiothek app.
The example builds a feed for Kalk & Welk, but the workflow can be easily adjusted by providing another podcast URL on the Get overview page HTTP Request node.
To subscribe to the feed, active your n8n workflow and then use the Production URL from the intitial Feed Webhook node in your podcatcher.
I've tested the resulting feed using Pocket Casts...
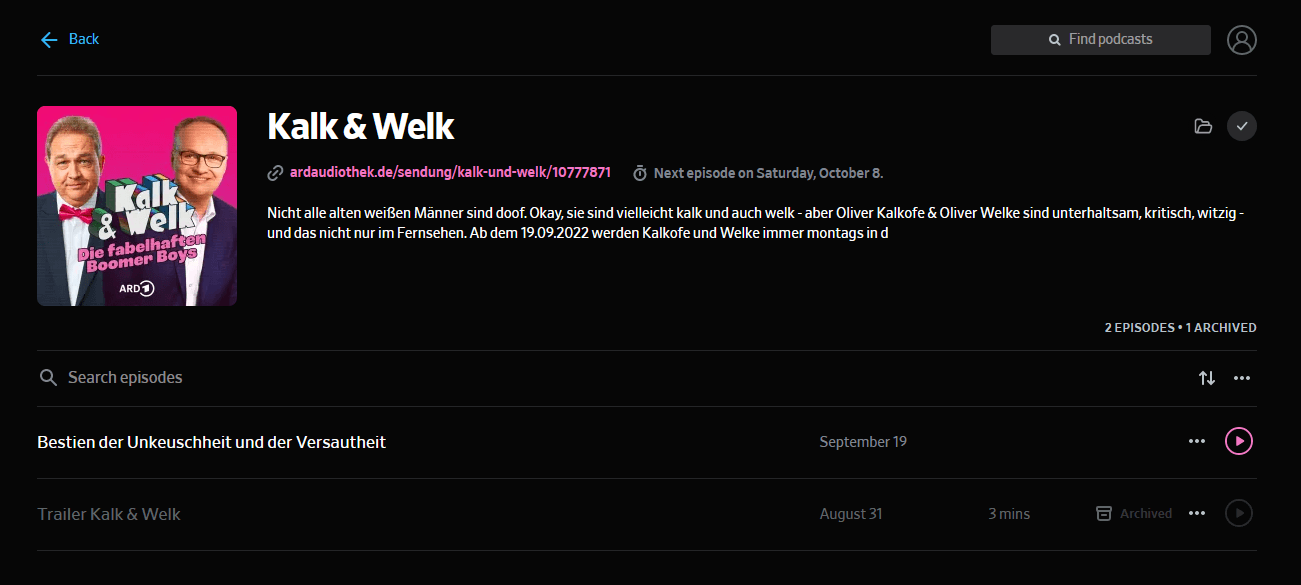
...and Miniflux:
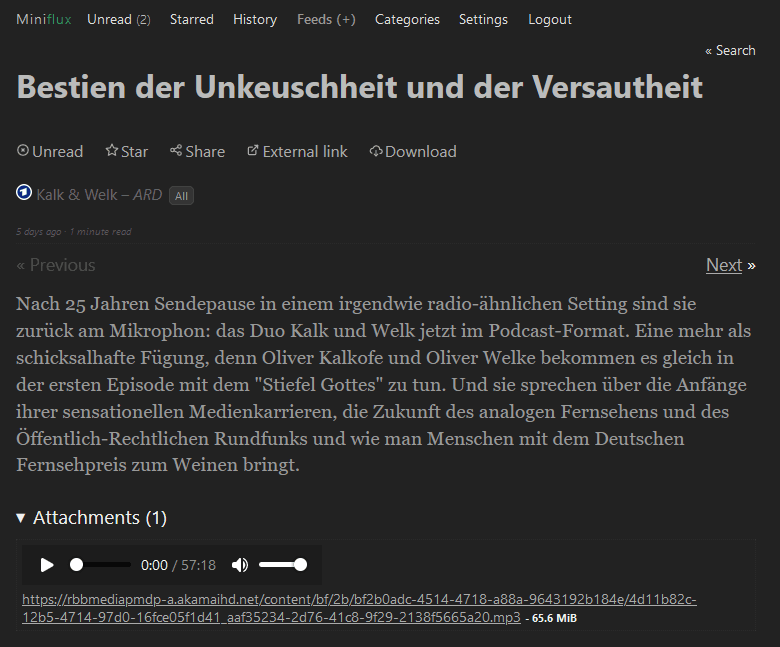
When using Miniflux, you can add your feed via this page to your account. Make sure you select Private when doing so to avoid sharing your n8n instance with the world.
The resulting feed passes the W3C Feed Validation Service:

The workflow can also be used as a foundation to free other podcasts from propriertary big media platforms, though not all of them will be as simple to deal with as the ARD Audiothek.