See llms.txt for all machine-readable content.


⚙️🛠️🚀🤖🦾
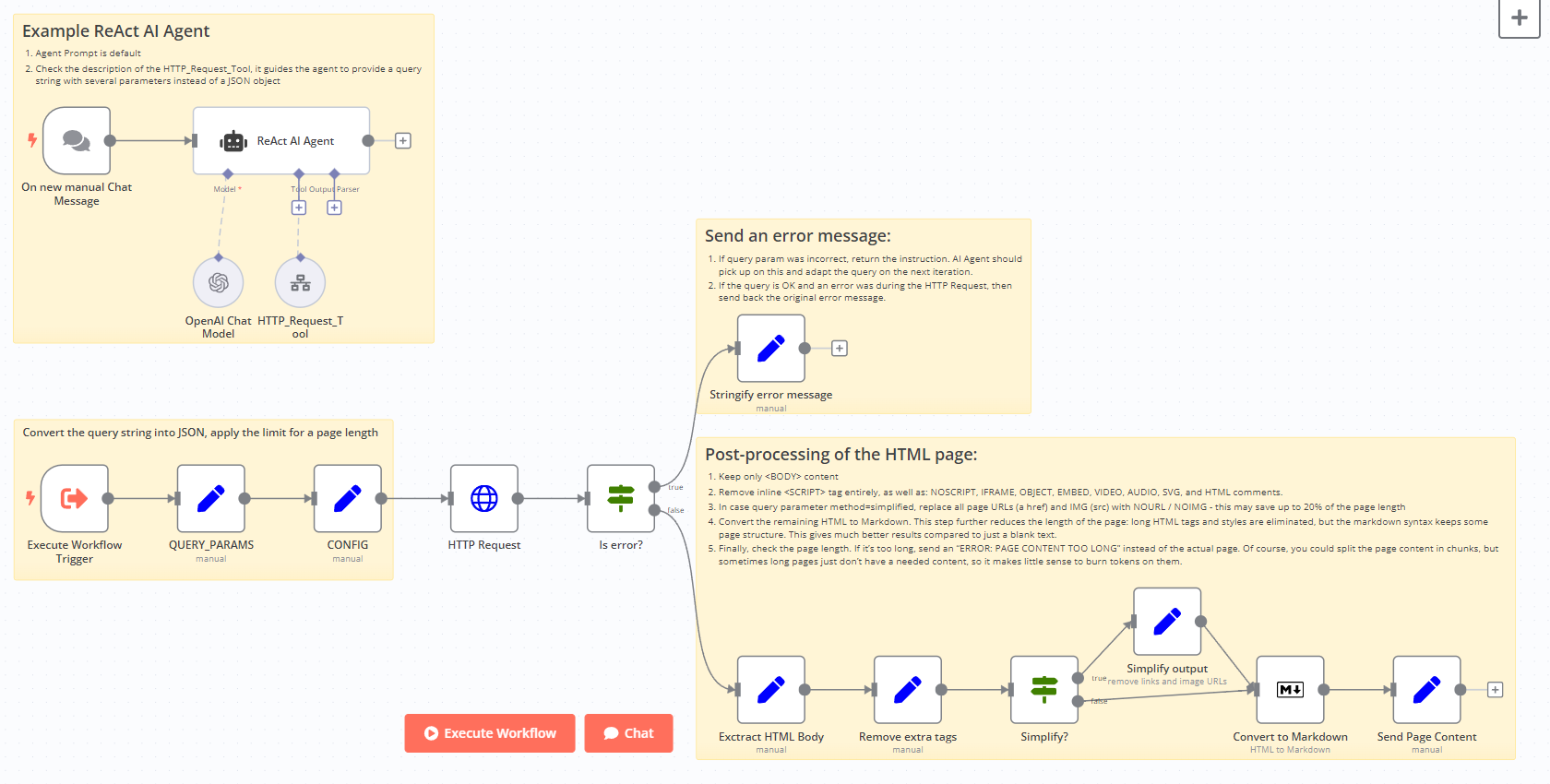
This template is a PoC of a ReAct AI Agent capable of fetching random pages (not only Wikipedia or Google search results).
On the top part there's a manual chat node connected to a LangChain ReAct Agent. The agent has access to a workflow tool for getting page content.
The page content extraction starts with converting query parameters into a JSON object. There are 3 pre-defined parameters:
- url – an address of the page to fetch
- method = full / simplified
- maxlimit - maximum length for the final page. For longer pages an error message is returned back to the agent
Page content fetching is a multistep process:
- An HTTP Request mode tries to get the page content.
If the page content was successfuly retrieved, a series of post-processing begin:
- Extract HTML BODY; content
- Remove all unnecessary tags to recuce the page size
- Further eliminate external URLs and IMG scr values (based on the method query parameter)
- Remaining HTML is converted to Markdown, thus recuding the page lengh even more while preserving the basic page structure
- The remaining content is sent back to an Agent if it's not too long (maxlimit = 70000 by default, see CONFIG node).
NB:
- You can isolate the HTTP Request part into a separate workflow.
- Check the Workflow Tool description, it guides the agent to provide a query string with several parameters instead of a JSON object.
Please reach out to Eduard is you need further assistance with you n8n workflows and automations!
Note that to use this template, you need to be on n8n version 1.19.4 or later.