Back to Templates


Dynamically Run SuiteQL Queries in NetSuite via HTTP Webhook in n8n
Important: This template uses a NetSuite community node, so it only works on self-hosted n8n. Cloud-based n8n instances currently do not support community nodes.
Summary
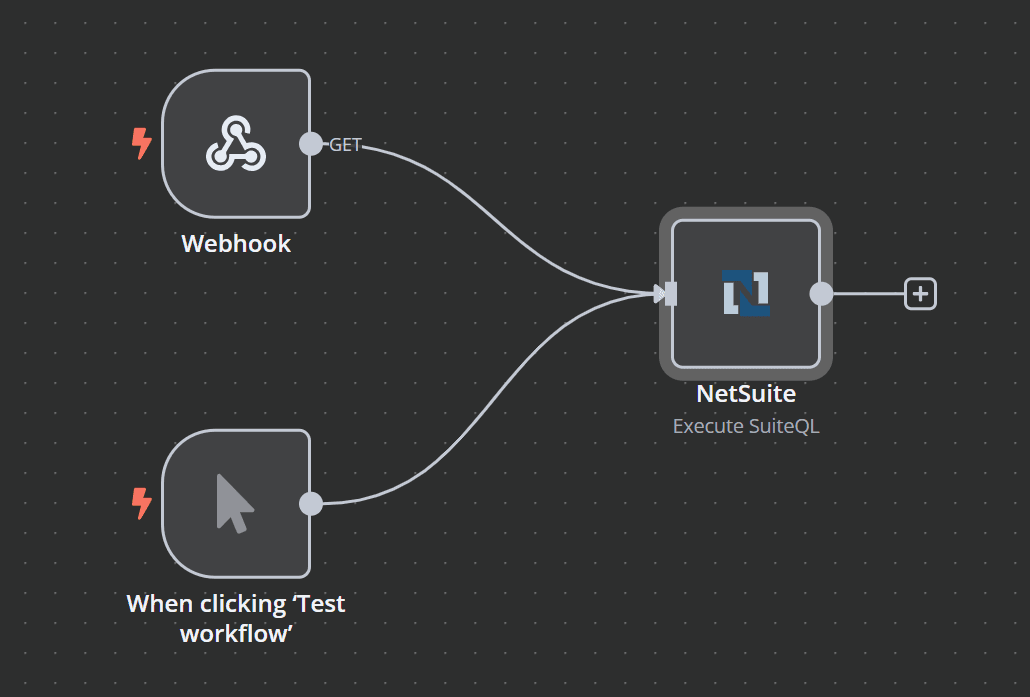
This workflow template allows you to dynamically run SuiteQL queries in NetSuite by sending an HTTP request to an n8n Webhook node. Once triggered, the workflow uses token-based authentication to execute your SuiteQL query and returns the results as JSON. This makes it easy to integrate real-time NetSuite data into dashboards, reporting tools, or other applications.
Who Is This For?
- Developers & Integrators: Easily embed NetSuite data retrieval into custom apps or internal tools.
- Enterprises & Consultants: Integrate dynamic reporting or data enrichment from NetSuite without manual exports.
- System Administrators: Automate routine queries and reduce manual intervention.
Use Cases & Benefits
1. Dynamic Data Access
Send any SuiteQL query on demand instead of hardcoding queries or manually running reports.
2. Seamless Integration
Quickly pull NetSuite data into front-end systems (like Excel dashboards, custom web apps, or internal tools) by calling the webhook endpoint.
3. Simplified Reporting
Automate data extraction and formatting, reducing the need for manual exports and improving efficiency.
How It Works
-
Trigger:
- An HTTP request to the webhook node initiates the workflow.
-
Input Processing:
- The workflow reads the SuiteQL query from the incoming request parameter (
suiteql).
- The workflow reads the SuiteQL query from the incoming request parameter (
-
Query Execution:
- The NetSuite node uses your token-based authentication credentials to run the SuiteQL query.
-
Response:
- Results are returned as JSON in the HTTP response, ready for further processing or immediate consumption.
Prerequisites & Setup
-
NetSuite Community Node
- This workflow requires the NetSuite community node. Make sure your self-hosted n8n instance supports community nodes.
-
NetSuite Token-Based Authentication
- Enable TBA in NetSuite. Obtain the required consumer key, consumer secret, token ID, and token secret.
-
n8n Webhook
- Copy the auto-generated webhook URL (e.g.
http://<your-n8n-domain>/webhook/unique-id) from the Webhook node.
- Copy the auto-generated webhook URL (e.g.
-
Usage
- Send an HTTP GET or POST request to the webhook with your SuiteQL query. For example:
curl "http://<your-n8n-domain>/webhook/unique-id?suiteql=SELECT%20*%20FROM%20account%20LIMIT%2010" - The workflow will execute the query and return JSON data.
- Send an HTTP GET or POST request to the webhook with your SuiteQL query. For example:
Customization
-
Change the Query:
Simply adjust thesuiteqlparameter in your HTTP request to run different SuiteQL statements. -
Data Transformation:
Insert nodes (e.g., Function, Set, or Format) to modify or reformat the data before returning it. -
Extend Integration:
Chain additional nodes to push the retrieved data to other services (Google Sheets, Slack, custom dashboards, etc.).
Additional Notes
- Remember that this template is only compatible with self-hosted n8n because it uses a community node. -
netsuite community node - If you have questions, suggestions, or need support, contact us at [email protected].