Back to Templates


Who this is for?
The Structured Data Extract & Data Mining workflow is crafted for researchers, content analysts, SEO strategists, and AI developers who need to transform semi-structured web data (like markdown content or scraped HTML) into actionable structured datasets.
It is ideal for:
-
Content Analysts - Organizing and mining large volumes of markdown or HTML content.
-
SEO & Trend Researchers - Exploring topics by location and category.
-
AI Engineers & NLP Developers - Looking to automate insight extraction from unstructured inputs.
-
Growth Marketers - Tracking topic-level trends for strategic campaigns.
-
Automation Specialists - Streamlining workflows from scrape to storage.
What problem is this workflow solving?
Extracting insights from markdown or HTML documents typically requires manual review, formatting, and parsing. This becomes unscalable when dealing with large datasets or when real-time response is needed. Additionally, trend and topic extraction usually involves external tools, custom scripts, and inconsistent formatting.
This workflow solves:
-
Automatic text extraction from markdown or structured content.
-
Location and category-based trend mining with semantic grouping.
-
AI-driven topic extraction and summarization
-
Real-time notification via webhook with rich structured payloads.
-
Persistent storage of mined data to disk for audits or further processing.
What this workflow does
-
Receives input: Sets the URL for the data extraction and analysis.
-
Uses Bright Data's Web Unlocker to extract content from relevant sites.
-
A Markdown/Text Extractor node parses the content into clean plaintext
-
The cleaned data is passed to Google Gemini to:
-
Identify trends by location and category
-
Extract key topics and themes
-
Format the response into structured JSON
-
The structured insights are sent via Webhook Notification to external systems (e.g., Slack, Web apps, Zapier)
-
The final output is saved to disk
-
Setup
- Sign up at Bright Data.
- Navigate to Proxies & Scraping and create a new Web Unlocker zone by selecting Web Unlocker API under Scraping Solutions.
- In n8n, configure the Header Auth account under Credentials (Generic Auth Type: Header Authentication).
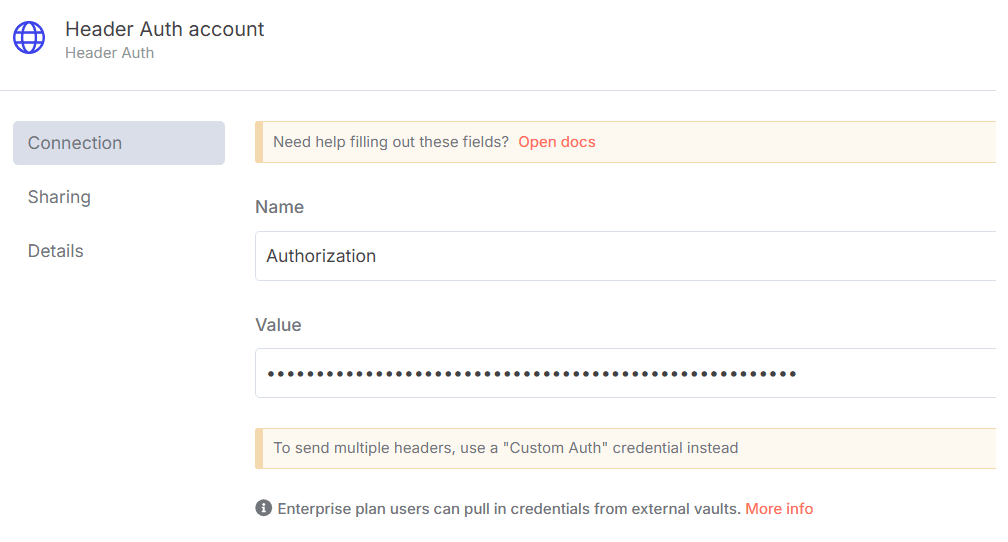
The Value field should be set with the
Bearer XXXXXXXXXXXXXX. The XXXXXXXXXXXXXX should be replaced by the Web Unlocker Token. - A Google Gemini API key (or access through Vertex AI or proxy).
- Update the Set URL and Bright Data Zone for setting the brand content URL and the Bright Data Zone name.
- Update the Webhook HTTP Request node with the Webhook endpoint of your choice.
How to customize this workflow to your needs
-
Update Source : Update the workflow input to read from Google Sheet or Airbase for dynamically tracking multiple brands or topics.
-
Gemini Prompt Customization :
-
Extract trends within a custom category (e.g., E-commerce design patterns in the US)
-
Output topics with popularity metrics
-
Structure the output as per your database schema (e.g., [{ topic, trend_score, location }])
-
-
Webhook Output : Send notifications to -
-
Slack – with AI summaries in rich blocks
-
Internal APIs – for use in dashboards
-
Zapier/Make – for multi-step automation
-
-
Persistence
-
Save output to:
- Remote FTP or SFTP storage
- Amazon S3, Google Cloud Storage etc.
-