Back to Templates



This workflow automates web scraping of Amazon search result pages by retrieving raw HTML, cleaning it to retain only the relevant product elements, and then using an LLM to extract structured product data (name, description, rating, reviews, and price), before saving the results back to Google Sheets.
It integrates Google Sheets to supply and collect URLs, BrightData to fetch page HTML, a custom n8n Function node to sanitize the HTML, LangChain (OpenRouter GPT-4) to parse product details, and Google Sheets again to store the output.
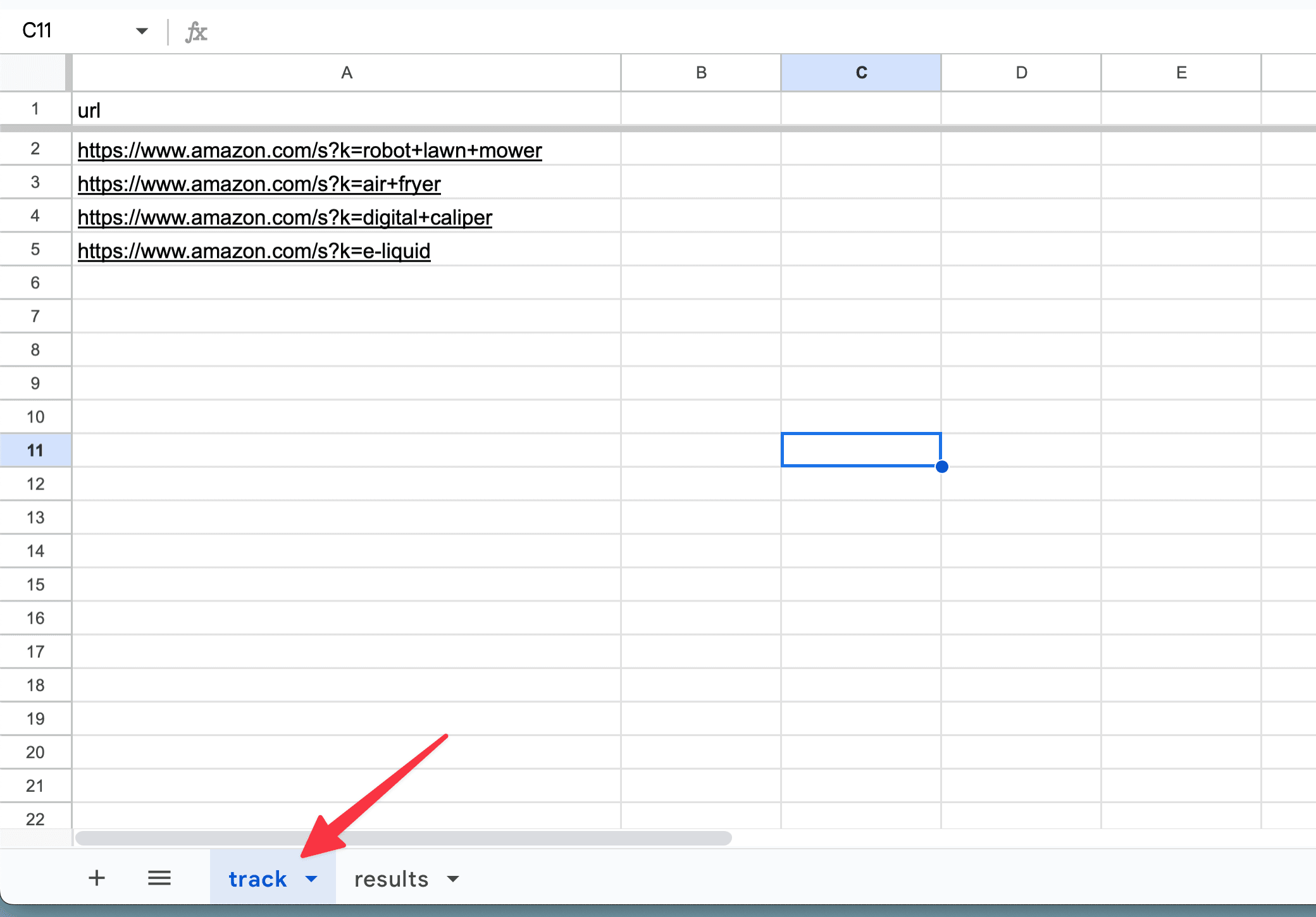
URL to scape
.
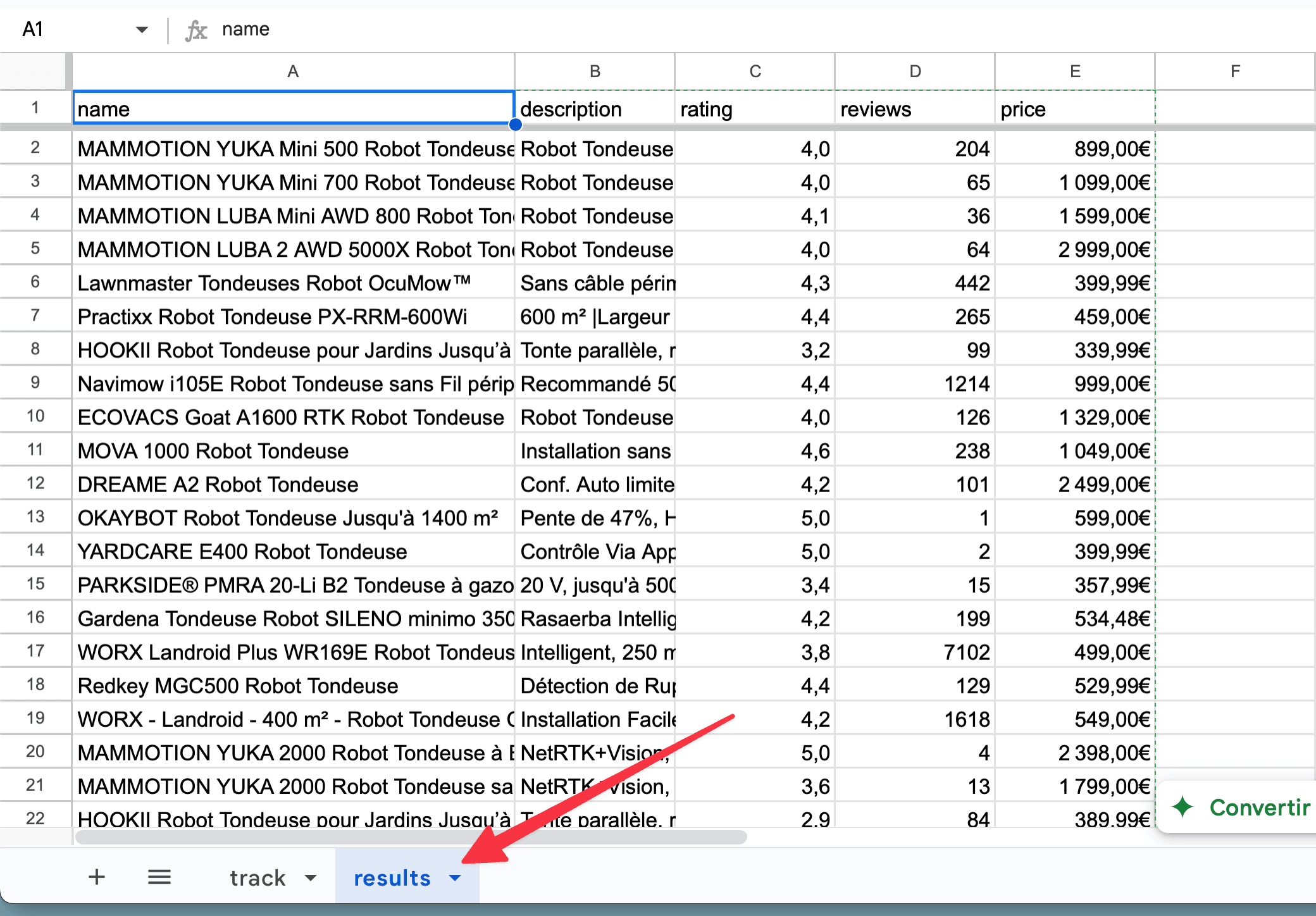
Result
Who Needs Amazon Search Result Scraping?
This scraping workflow is ideal for teams and businesses that need to monitor Amazon product listings at scale:
- E-commerce Analysts – Track competitor pricing, ratings, and inventory trends.
- Market Researchers – Collect data on product popularity and reviews for market analysis.
- Data Teams – Automate ingestion of product metadata into BI pipelines or data lakes.
- Affiliate Marketers – Keep affiliate catalogs up to date with latest product details and prices.
If you need reliable, structured data from Amazon search results delivered directly into your spreadsheets, this workflow saves you hours of manual copy-and-paste.
Why Use This Workflow?
- End-to-End Automation – From URL list to clean JSON output in Sheets.
- Robust HTML Cleaning – Strips scripts, styles, unwanted tags, and noise.
- Accurate Structured Parsing – Leverages GPT-4 via LangChain for reliable extraction.
- Scalable & Repeatable – Processes thousands of URLs in batches.
Step-by-Step: How This Workflow Scrapes Amazon
- Get URLs from Google Sheets – Reads a list of search result URLs.
- Loop Over Items – Iterates through each URL in controlled batches.
- Fetch Raw HTML – Uses BrightData’s Web Unlocker proxy to retrieve the page.
- Clean HTML – A Function node removes doctype, scripts, styles, head, comments, classes, and non-whitelisted tags, collapsing extra whitespace.
- Extract with LLM – Passes cleaned HTML into LangChain → GPT-4 to output JSON for each product:
name,description,rating,reviews,price
- Save Results – Appends the JSON fields as columns back into a “results” sheet in Google Sheets.
Customization: Tailor to Your Needs
- Adaptable Sites – This workflow can be adapted to any e-commerce or other website, for example Walmart or eBay.
- Whitelist Tags – Modify the allowedTags array in the Code node to keep additional HTML elements.
- Schema Changes – Update the Structured Output Parser schema to include more fields (e.g., availability, SKU).
- Alternate Data Sink – Instead of Sheets, route output to a database, CSV file, or webhook.
🔑 Prerequisites
- Google Sheets Credentials – OAuth credentials configured in n8n.
- BrightData API token – Stored in n8n credentials as
BRIGHTDATA_TOKEN. - OpenRouter API Key – Configured for the LangChain node to call GPT-4.
- n8n Instance – Self-hosted or cloud with sufficient quota for HTTP requests and LLM calls.
🚀 Installation & Setup
- Configure Credentials
- In n8n, set up Google Sheets OAuth under “Credentials.”
- Add BrightData token as a new HTTP Request credential.
- Create an OpenRouter API key credential for the LangChain node.
- Import the Workflow
- Copy the JSON workflow into n8n’s “Import” dialog.
- Map your Google Sheet IDs and GIDs to the
{{WEB_SHEET_ID}},{{TRACK_SHEET_GID}}, and{{RESULTS_SHEET_GID}}placeholders. - Ensure the
BRIGHTDATA_TOKENcredential is selected on the HTTP Request node.
- Test & Run
- Add a few Amazon search URLs to your “track” sheet.
- Execute the workflow and verify product data appears in your “results” sheet.
- Tweak batch size or parser schema as needed.
⚠ Important
- API Rate Limits – Monitor your BrightData and OpenRouter usage to avoid throttling.
- Amazon’s Terms – Ensure your scraping complies with Amazon’s policies and legal requirements.
Summary
This workflow delivers a fully automated, scalable solution to extract structured product data from Amazon search pages directly into Google Sheets—streamlining your competitive analysis and data collection. 🚀
.
🇫🇷 Contactez nous pour automatiser vos processus