Back to Templates


AI-Powered Web Data Pipeline with n8n
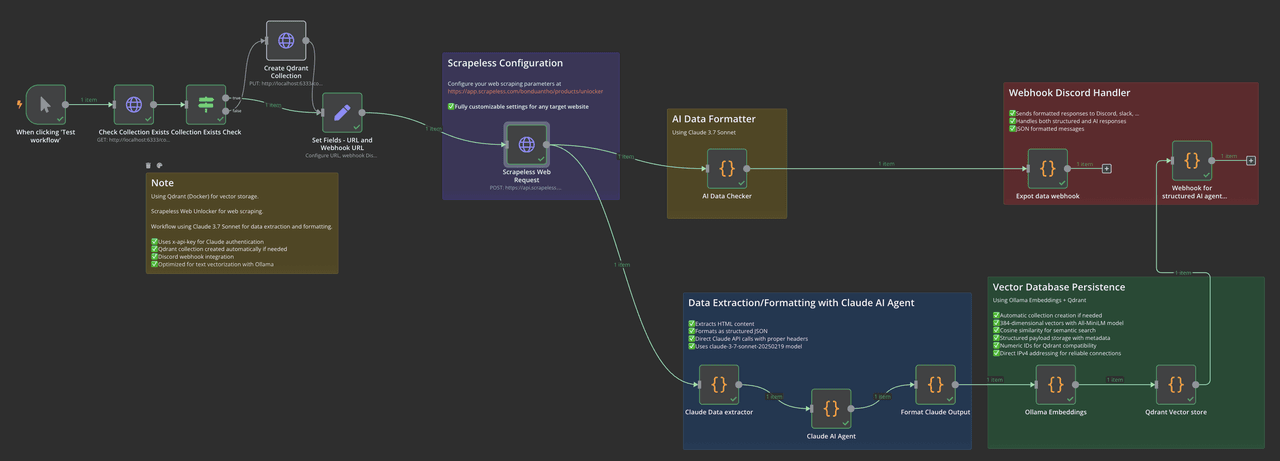
How It Works
This n8n workflow builds an AI-powered web data pipeline that automates the entire process of:
- Extraction
- Structuring
- Vectorization
- Storage
It integrates multiple advanced tools to transform messy web pages into clean, searchable vector databases.
Integrated Tools
-
Scrapeless
Bypasses JavaScript-heavy websites and anti-bot protections to reliably extract HTML content. -
Claude AI
Uses LLMs to analyze unstructured HTML and generate clean, structured JSON data. -
Ollama Embeddings
Generates local vector embeddings from structured text using theall-minilmmodel. -
Qdrant Vector DB
Stores semantic vector data for fast and meaningful search capabilities. -
Webhook Notifications
Sends real-time updates when workflows complete or errors occur.
From messy webpages to structured vector data — this pipeline is perfect for building intelligent agents, knowledge bases, or research automation tools.
Setup Steps
1. Install n8n
Requires Node.js v18 / v20 / v22
npm install -g n8n
n8n
After installation, access the n8n interface via:
2. Set Up Scrapeless
- Register at: Scrapeless
- Copy your API token
- Paste the token into the
HTTP Requestnode labeled "Scrapeless Web Request"
3. Set Up Claude API (Anthropic)
- Sign up at Anthropic Console
- Generate your Claude API key
- Add the API key to the following nodes:
Claude ExtractorAI Data CheckerClaude AI Agent
4. Install and Run Ollama
macOS
brew install ollama
Linux
curl -fsSL https://ollama.com/install.sh | sh
Windows
Download the installer from: https://ollama.com
Start Ollama Server
ollama serve
Pull Embedding Model
ollama pull all-minilm
5. Install Qdrant (via Docker)
docker pull qdrant/qdrant
docker run -d \
--name qdrant-server \
-p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrant
Test if Qdrant is running:
curl http://localhost:6333/healthz
6. Configure the n8n Workflow
-
Modify the Trigger (Manual or Scheduled)
-
Input your Target URLs and Collection Name in the designated nodes
-
Paste all required API Tokens / Keys into their corresponding nodes
-
Ensure your Qdrant and Ollama services are running
Ideal Use Cases
-
Custom AI Chatbots
-
Private Search Engines
-
Research Tools
-
Internal Knowledge Bases
-
Content Monitoring Pipelines