Back to Templates


Goodreads Quote Extraction with Bright Data and Gemini
This workflow demonstrates how to fetch data specifically from Goodreads web pages using Bright Data and then extract specific information (quotes) from that data using a Google Gemini AI model.
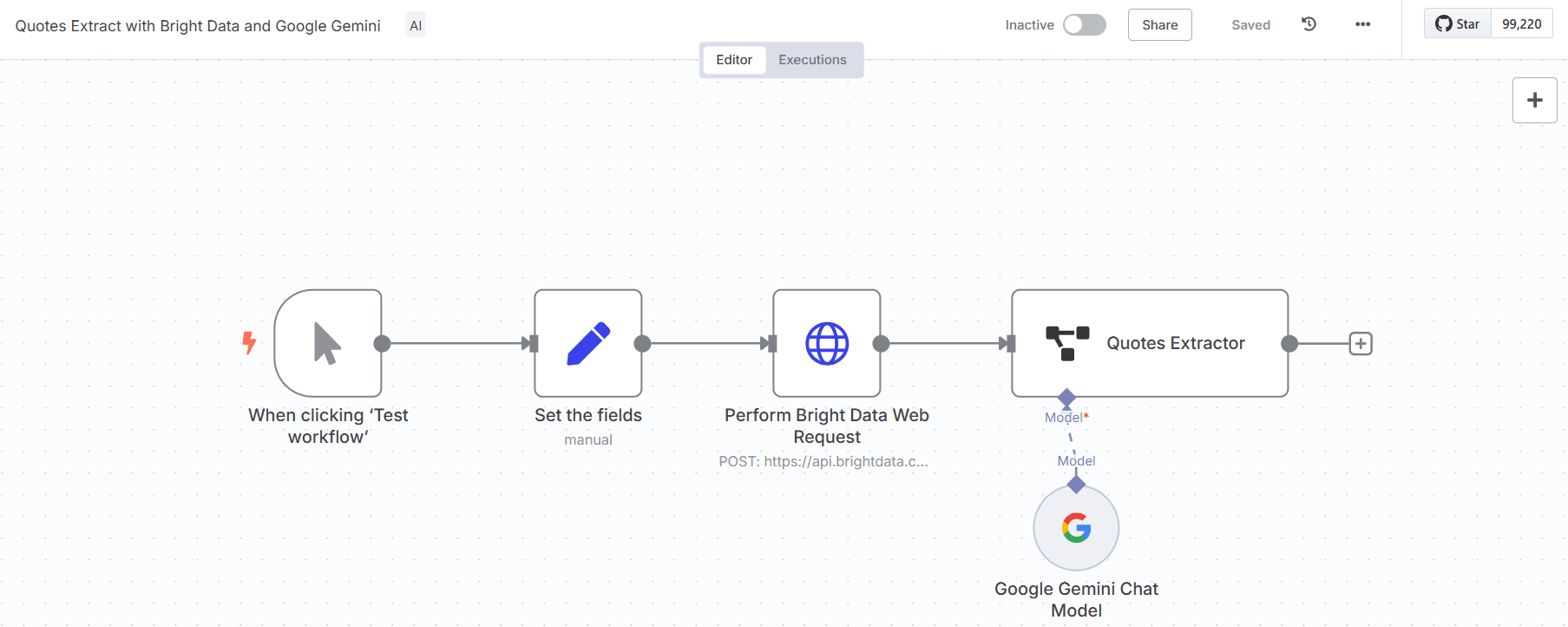
How it works
- The workflow is triggered manually.
- It sends a request to a Bright Data collector to scrape data from a predefined list of Goodreads URLs.
- The collected text data from Goodreads is then passed to a Google Gemini AI node.
- The AI node processes the text and extracts quotes based on a specified JSON schema output format.
Set up steps
Setting up this workflow should take only a few minutes.
- You will need a Bright Data API key to configure the 'Header Auth' credential.
- You will need a Google Gemini API key to configure the 'Google Gemini(PaLM) Api account' credential.
- Ensure the correct Bright Data collector ID is set in the 'Perform Bright Data Web Request' node URL.
- Make sure the full list of target Goodreads URLs is correctly added to the 'Perform Bright Data Web Request' node's body.
- Link your created credentials to the respective nodes ('Perform Bright Data Web Request' and 'Quotes Extractor').
- Keep detailed descriptions for specific node configurations in sticky notes inside your workflow canvas.