Back to Templates


Overview
This intelligent chatbot workflow enables natural language conversations with your documents, supporting multiple file formats including PDFs, Word documents, Excel spreadsheets, and text files. Built with advanced RAG (Retrieval-Augmented Generation) technology, this chatbot can understand, analyze, and answer questions about your document content with contextual accuracy and intelligent responses.
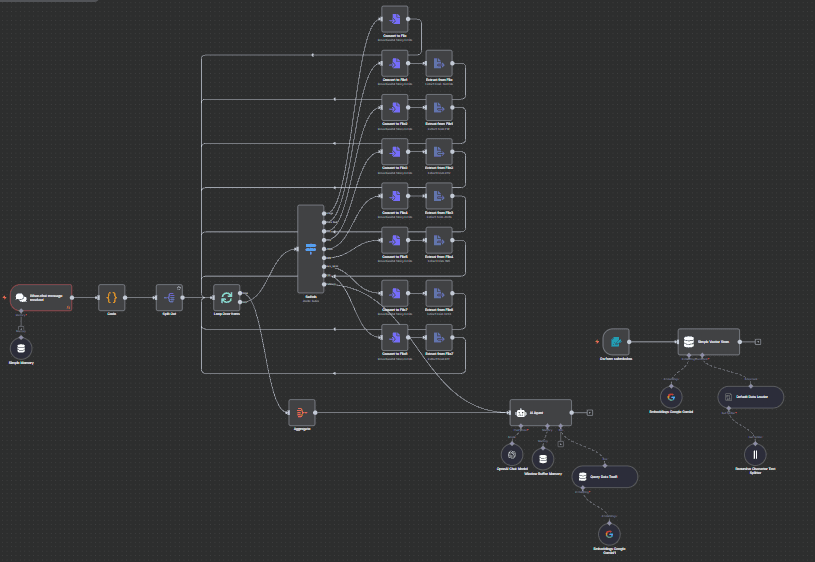
How It Works
Intelligent Document Processing & Conversation Pipeline:
- Multi-Format Document Ingestion: Automatically processes and indexes various document formats (PDF, DOCX, XLSX, TXT, etc.)
- Smart Content Chunking: Breaks down documents into meaningful segments while preserving context and relationships
- Vector Database Storage: Creates searchable embeddings for fast and accurate information retrieval
- Contextual Conversation Engine: Uses AI to understand user queries and retrieve relevant document sections
- Natural Language Responses: Generates human-like responses with citations and source references
- Multi-Turn Conversations: Maintains conversation history and context across multiple interactions
- Real-Time Processing: Instant responses with live document updates and dynamic content refresh
Setup Instructions
Estimated Setup Time: 15-20 minutes
Prerequisites
- n8n instance (v0.200.0 or higher recommended)
- OpenAI/Gemini API key for embeddings and chat completion
- Vector database service (optional: Pinecone, Weaviate, or Qdrant)
- File storage service (optional: Google Drive, Dropbox, AWS S3)
- Web server for chatbot interface (optional)
Configuration Steps
-
Configure Document Input Sources
- Set up file upload webhook for direct document submission
- Configure cloud storage watchers for automatic document processing
- Add support for multiple file formats and size limits
- Set up document validation and security checks
-
Setup Document Processing Pipeline
- Configure text extraction engines for different file types
- Set up intelligent chunking parameters (chunk size, overlap, boundaries)
- Add metadata extraction for document categorization
- Configure OCR for scanned documents (optional)
-
Configure Vector Database
- Set up your chosen vector database credentials
- Configure embedding model settings (Gemini models/text-embedding-004 recommended)
- Set up collection/index structure for document storage
- Configure search parameters and similarity thresholds
-
Setup AI Chat Engine
- Add your AI service API credentials (Gemini, Claude, etc.)
- Configure conversation prompts and system instructions
- Set up context window management and token optimization
- Add response formatting and citation rules
-
Configure Chat Interface
- Set up webhook endpoints for chat API
- Configure session management and conversation history
- Add authentication and rate limiting (optional)
- Set up real-time updates and streaming responses
-
Setup Monitoring & Analytics
- Configure conversation logging and analytics
- Set up performance monitoring for response times
- Add usage tracking and cost monitoring
- Configure error handling and failover mechanisms
Use Cases
Business & Enterprise
- Knowledge Base Queries: Ask questions about company policies, procedures, and documentation
- Contract Analysis: Query legal documents, contracts, and compliance materials
- Training Materials: Interactive learning with training manuals and educational content
- Financial Reports: Analyze and discuss financial statements, budgets, and forecasts
Research & Academia
- Research Paper Analysis: Discuss findings, methodologies, and citations from academic papers
- Literature Reviews: Compare and contrast multiple research documents
- Thesis Support: Get insights from reference materials and research data
- Grant Proposals: Analyze requirements and optimize proposal content
Legal & Compliance
- Legal Document Review: Query contracts, agreements, and legal texts
- Regulatory Compliance: Understand compliance requirements from regulatory documents
- Case Law Research: Analyze legal precedents and court decisions
- Policy Analysis: Interpret organizational policies and procedures
Technical Documentation
- API Documentation: Interactive queries about technical specifications
- User Manuals: Get help and guidance from product documentation
- Code Documentation: Understand codebases and technical implementations
- Troubleshooting Guides: Interactive problem-solving with technical guides
Personal Productivity
- Document Summarization: Get quick summaries of long documents
- Information Extraction: Find specific data points across multiple documents
- Content Research: Research topics across your personal document library
- Meeting Notes: Query and analyze meeting transcripts and notes
Key Features
Advanced Document Processing
- Multi-Format Support: PDF, DOCX, XLSX, TXT, PPTX, and more
- Intelligent Chunking: Context-aware document segmentation
- Metadata Extraction: Automatic categorization and tagging
- OCR Integration: Process scanned documents and images with text
Intelligent Conversation
- Contextual Understanding: Maintains conversation context and document relationships
- Source Attribution: Provides citations and references for all answers
- Multi-Document Queries: Compare and analyze across multiple documents
- Follow-up Questions: Natural conversation flow with clarifying questions
Performance & Scalability
- Fast Retrieval: Vector-based semantic search for instant responses
- Scalable Architecture: Handle large document collections efficiently
- Batch Processing: Process multiple documents simultaneously
- Caching System: Optimized response times with intelligent caching
Security & Privacy
- Document Encryption: Secure storage and transmission of sensitive documents
- Access Control: User-based permissions and document access restrictions
- Audit Logging: Complete conversation and access audit trails
- Data Retention: Configurable data retention and deletion policies
Technical Architecture
Document Processing Flow
- File Upload → Format Detection → Text Extraction → Content Chunking
- Metadata Extraction → Embedding Generation → Vector Storage → Index Creation
Conversation Flow
- User Query → Intent Analysis → Vector Search → Context Retrieval
- Response Generation → Source Attribution → Answer Formatting → Delivery
Supported File Formats
- Documents: PDF, DOC, DOCX, RTF, TXT, MD
- Spreadsheets: XLS, XLSX, CSV
- Presentations: PPT, PPTX
- Images: PNG, JPG (with OCR)
- Archives: ZIP (auto-extracts supported formats)
- Web: HTML, XML
Integration Options
Chat Interfaces
- Web Widget: Embeddable chat widget for websites
- API Endpoints: RESTful API for custom integrations
- Slack/Teams: Direct integration with team collaboration tools
- Mobile Apps: API-first design for mobile application integration
Data Sources
- Cloud Storage: Google Drive, Dropbox, OneDrive, AWS S3
- Document Systems: SharePoint, Confluence, Notion
- Email: Process attachments from email systems
- CRM/ERP: Integration with business systems
Performance Specifications
- Response Time: < 3 seconds for typical queries
- Document Capacity: Supports collections of 10,000+ documents
- Concurrent Users: Scales to handle multiple simultaneous conversations
- Accuracy: >90% relevance for domain-specific queries
Advanced Configuration Options
Customization
- Custom Prompts: Tailor AI behavior for specific use cases
- Branding: Customize chat interface with your company branding
- Language Support: Multi-language document processing and responses
- Domain Expertise: Fine-tune for specific industries or domains
Analytics & Monitoring
- Usage Analytics: Track popular queries and document usage
- Performance Metrics: Monitor response times and accuracy
- User Feedback: Collect ratings and improve responses
- A/B Testing: Test different configurations and prompts
Troubleshooting & Support
Common Issues
- Slow Responses: Check vector database performance and API limits
- Inaccurate Answers: Review chunking strategy and embedding quality
- Format Errors: Verify document formats and processing capabilities
- Memory Issues: Monitor token usage and context window limits
Optimization Tips
- Use clear, specific questions for best results
- Ensure documents are well-formatted with proper headers
- Regular vector database maintenance for optimal performance
- Monitor API usage to optimize costs and performance