Back to Templates


⚠️ Note: This template requires a community node and works only on self-hosted n8n installations. It uses the Typhoon OCR Python package, pdfseparate from poppler-utils, and custom command execution. Make sure to install all required dependencies locally.
Who is this for?
This template is designed for developers, back-office teams, and automation builders (especially in Thailand or Thai-speaking environments) who need to process multi-file, multi-page Thai PDFs and automatically export structured results to Google Sheets.
It is ideal for:
- Government and enterprise document processing
- Thai-language invoices, memos, and official letters
- AI-powered automation pipelines that require Thai OCR
What problem does this solve?
Typhoon OCR is one of the most accurate OCR tools for Thai text, but integrating it into an end-to-end workflow usually requires manual scripting and handling multi-page PDFs. This template solves that by:
- Splitting PDFs into individual pages
- Running Typhoon OCR on each page
- Aggregating text back into a single file
- Using AI to extract structured fields
- Automatically saving structured data into Google Sheets
What this workflow does
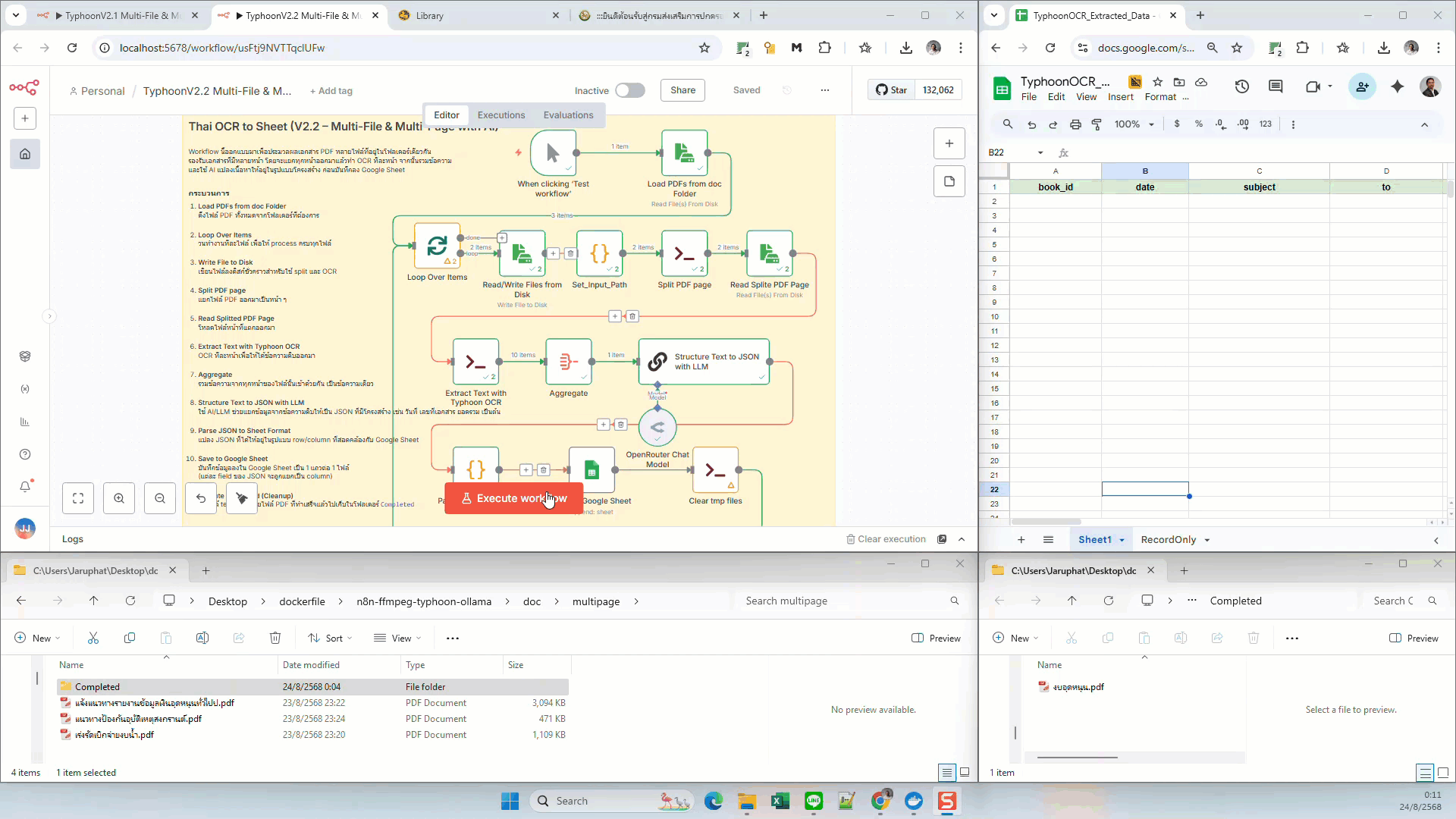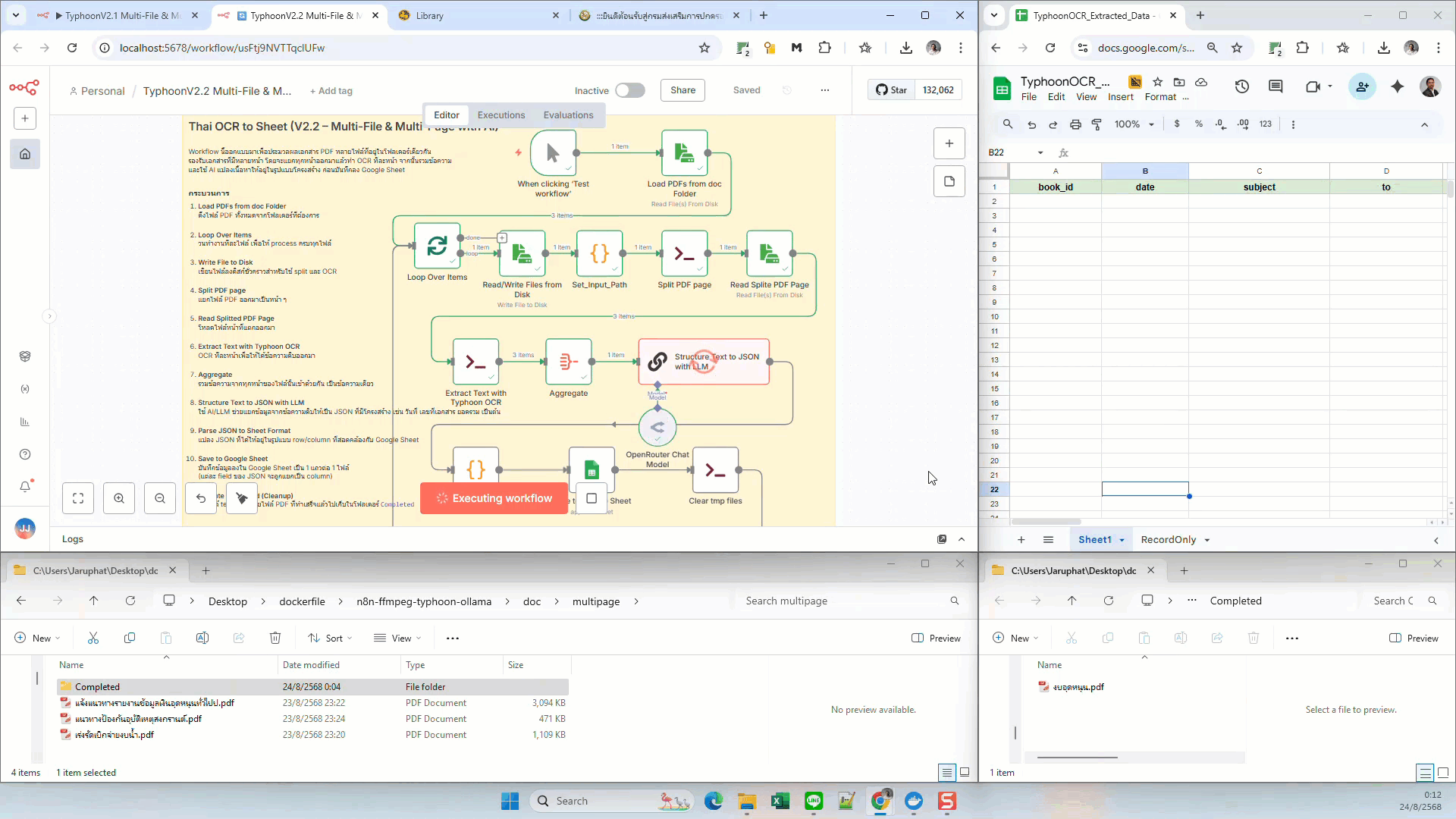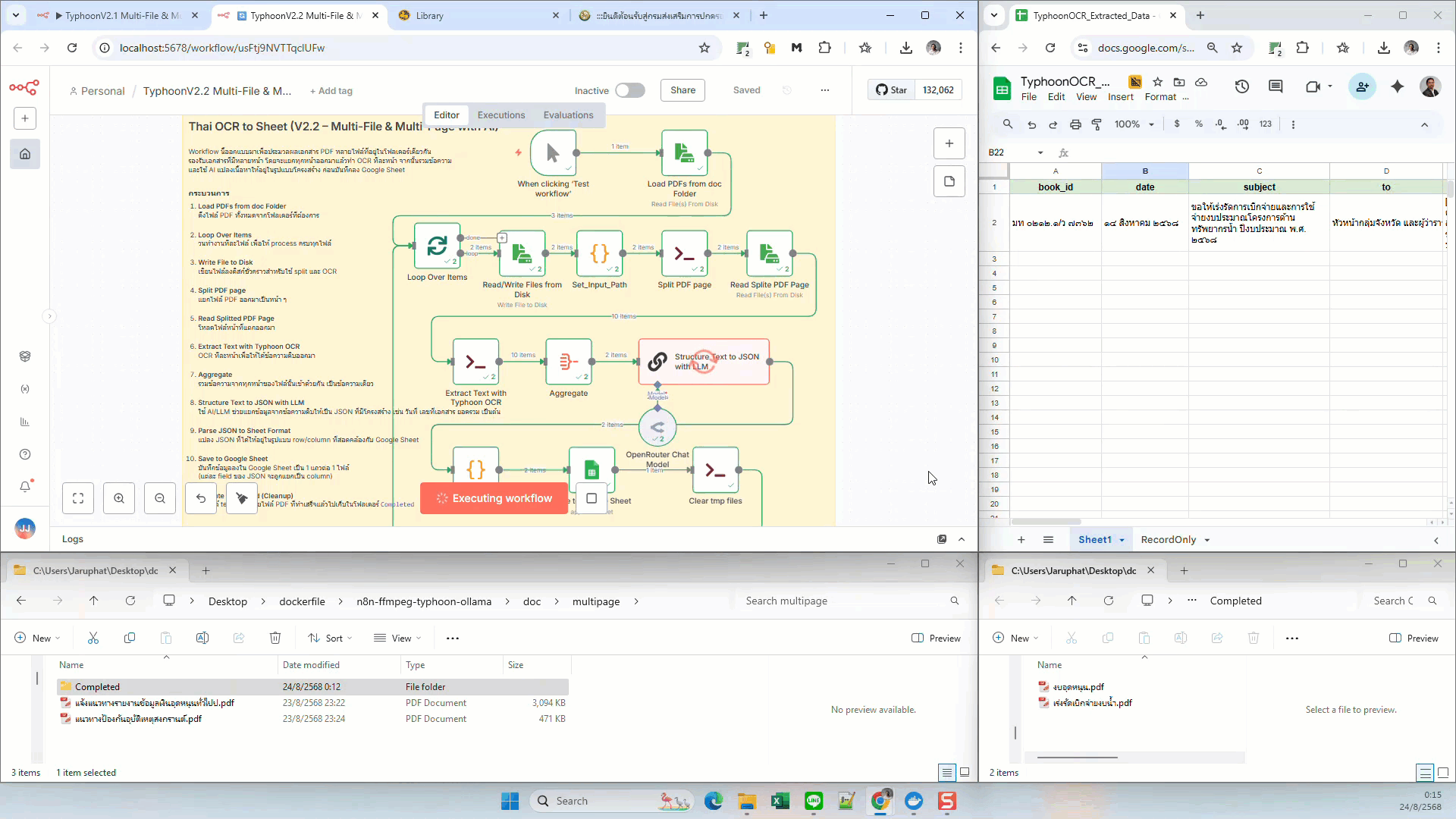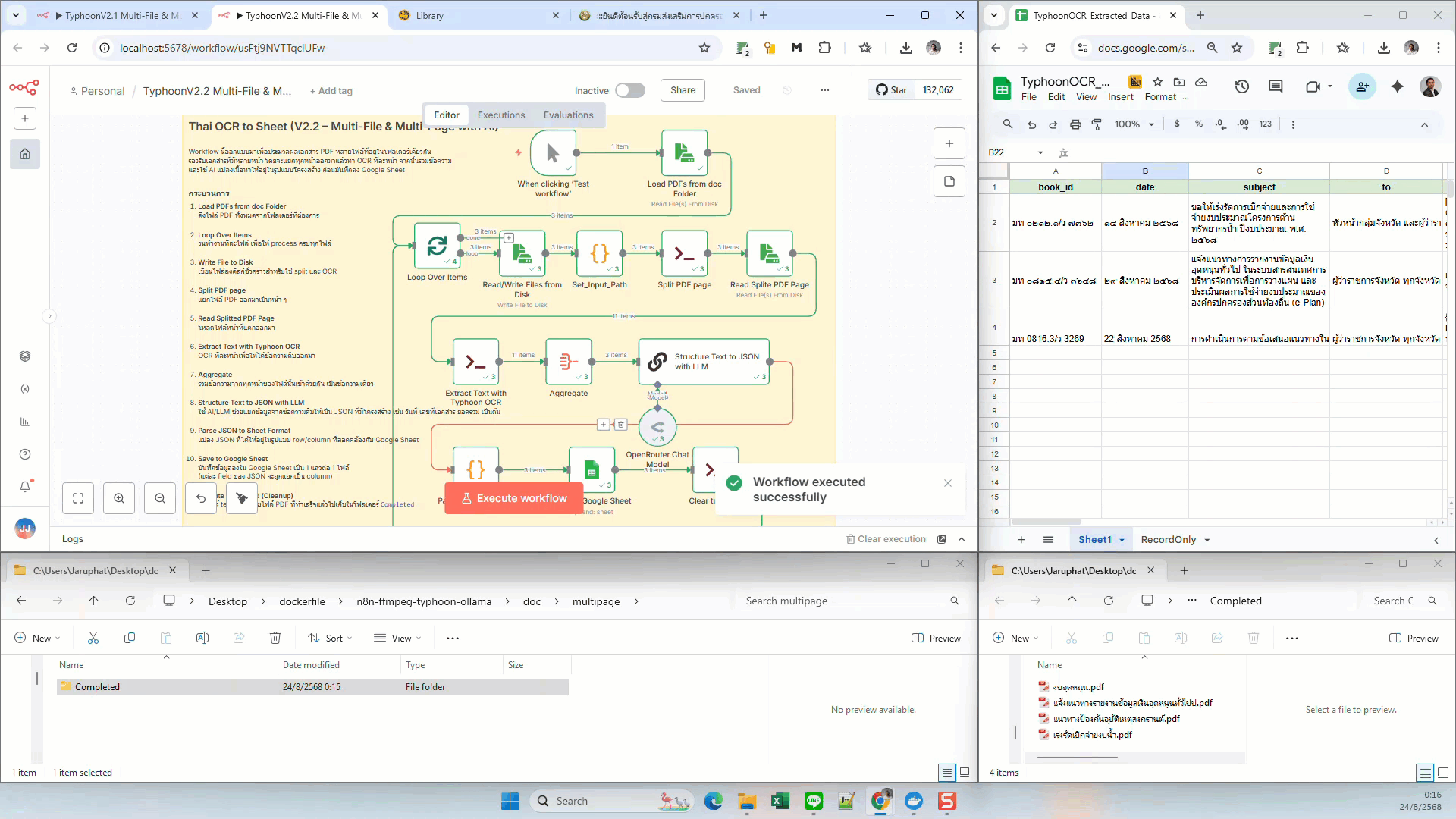
- Trigger: Manual execution or any n8n trigger node
- Load Files: Read PDFs from a local
doc/multipagefolder - Split PDF Pages: Use
pdfinfoandpdfseparateto break PDFs into pages - Typhoon OCR: Run OCR on each page via Execute Command
- Aggregate: Combine per-page OCR text
- LLM Extraction: Use AI (e.g., GPT-4, OpenRouter) to extract fields into JSON
- Parse JSON: Convert structured JSON into a tabular format
- Google Sheets: Append one row per file into a Google Sheet
- Cleanup: Delete temp split pages and move processed PDFs into a Completed folder
Setup
-
Install Requirements
- Python 3.10+
typhoon-ocr:pip install typhoon-ocr- poppler-utils: provides
pdfinfo,pdfseparate - qpdf: backup page counting
-
Create folders
/doc/multipagefor incoming files/doc/tmpfor split pages/doc/multipage/Completedfor processed files
-
Google Sheet
- Create a Google Sheet with column headers like:
book_id | date | subject | to | attach | detail | signed_by | signed_by2 | contact_phone | contact_email | contact_fax | download_url
- Create a Google Sheet with column headers like:
-
API Keys
- Export your
TYPHOON_OCR_API_KEYandOPENAI_API_KEY(or use credentials in n8n)
- Export your
How to customize this workflow
- Replace the LLM provider in the “Structure Text to JSON with LLM” node (supports OpenRouter, OpenAI, etc.)
- Adjust the JSON schema and parsing logic to match your documents
- Update Google Sheets mapping to fit your desired fields
- Add trigger nodes (Dropbox, Google Drive, Webhook) to automate file ingestion
About Typhoon OCR
Typhoon is a multilingual LLM and NLP toolkit optimized for Thai. It includes typhoon-ocr, a Python OCR package designed for Thai-centric documents. It is open-source, highly accurate, and works well in automation pipelines. Perfect for government paperwork, PDF reports, and multi-language documents in Southeast Asia.
Deployment Option
You can also deploy this workflow easily using the Docker image provided in my GitHub repository: https://github.com/Jaruphat/n8n-ffmpeg-typhoon-ollama
This Docker setup already includes n8n, ffmpeg, Typhoon OCR, and Ollama combined together, so you can run the whole environment without installing each dependency manually.