See llms.txt for all machine-readable content.


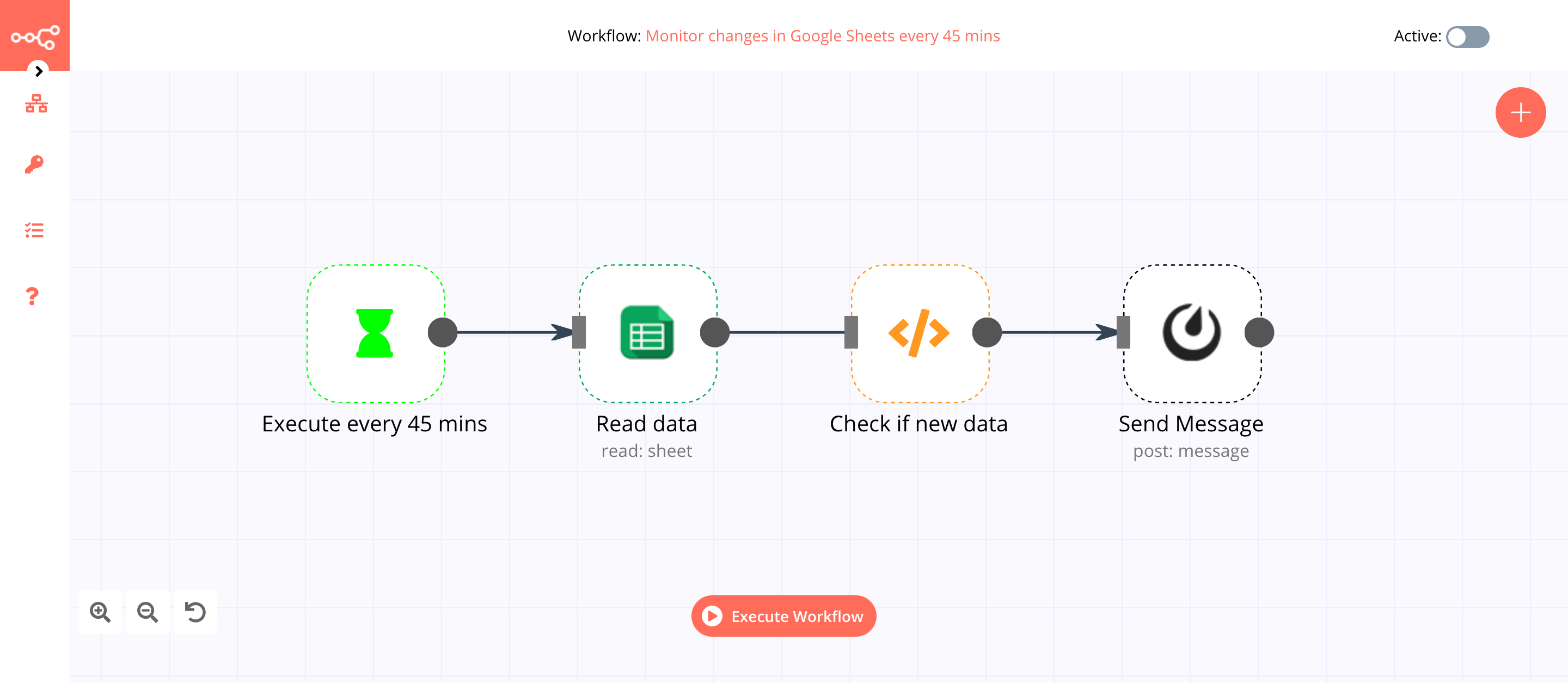
Based on your use case, you might want to trigger a workflow if new data gets added to your database. This workflow allows you to send a message to Mattermost when new data gets added in Google Sheets.
The Interval node triggers the workflow every 45 minutes. You can modify the timing based on your use case. You can even use the Cron node to trigger the workflow.
If you wish to fetch new Tweets from Twitter, replace the Google Sheet node with the respective node. Update the Function node accordingly.