Back to integrations
Postgres and Wordpress integration
Save yourself the work of writing custom integrations for Postgres and Wordpress and use n8n instead. Build adaptable and scalable Development, Data & Storage, workflows that work with your technology stack. All within a building experience you will love.




How to connect Postgres and Wordpress
Create a new workflow and add the first step
In n8n, click the "Add workflow" button in the Workflows tab to create a new workflow. Add the starting point – a trigger on when your workflow should run: an app event, a schedule, a webhook call, another workflow, an AI chat, or a manual trigger. Sometimes, the HTTP Request node might already serve as your starting point.

Popular ways to use the Postgres and Wordpress integration
Build your own Postgres and Wordpress integration
Create custom Postgres and Wordpress workflows by choosing triggers and actions. Nodes come with global operations and settings, as well as app-specific parameters that can be configured. You can also use the HTTP Request node to query data from any app or service with a REST API.
Postgres supported actions
Delete
Delete an entire table or rows in a table
Execute Query
Execute an SQL query
Insert
Insert rows in a table
Insert or Update
Insert or update rows in a table
Select
Select rows from a table
Update
Update rows in a table
Wordpress supported actions
Create
Create a post
Get
Get a post
Get Many
Get many posts
Update
Update a post
Create
Create a page
Get
Get a page
Get Many
Get many pages
Update
Update a page
Create
Create a user
Get
Get a user
Get Many
Get many users
Update
Update a user
Postgres and Wordpress integration details
Other integrations with Postgres




Other integrations with Wordpress



Automate lead management
Using too many marketing tools? n8n lets you orchestrate all your apps into one cohesive, automated workflow.
Save engineering resources
Reduce time spent on customer integrations, engineer faster POCs, keep your customer-specific functionality separate from product all without having to code.
Postgres and Wordpress integration tutorials
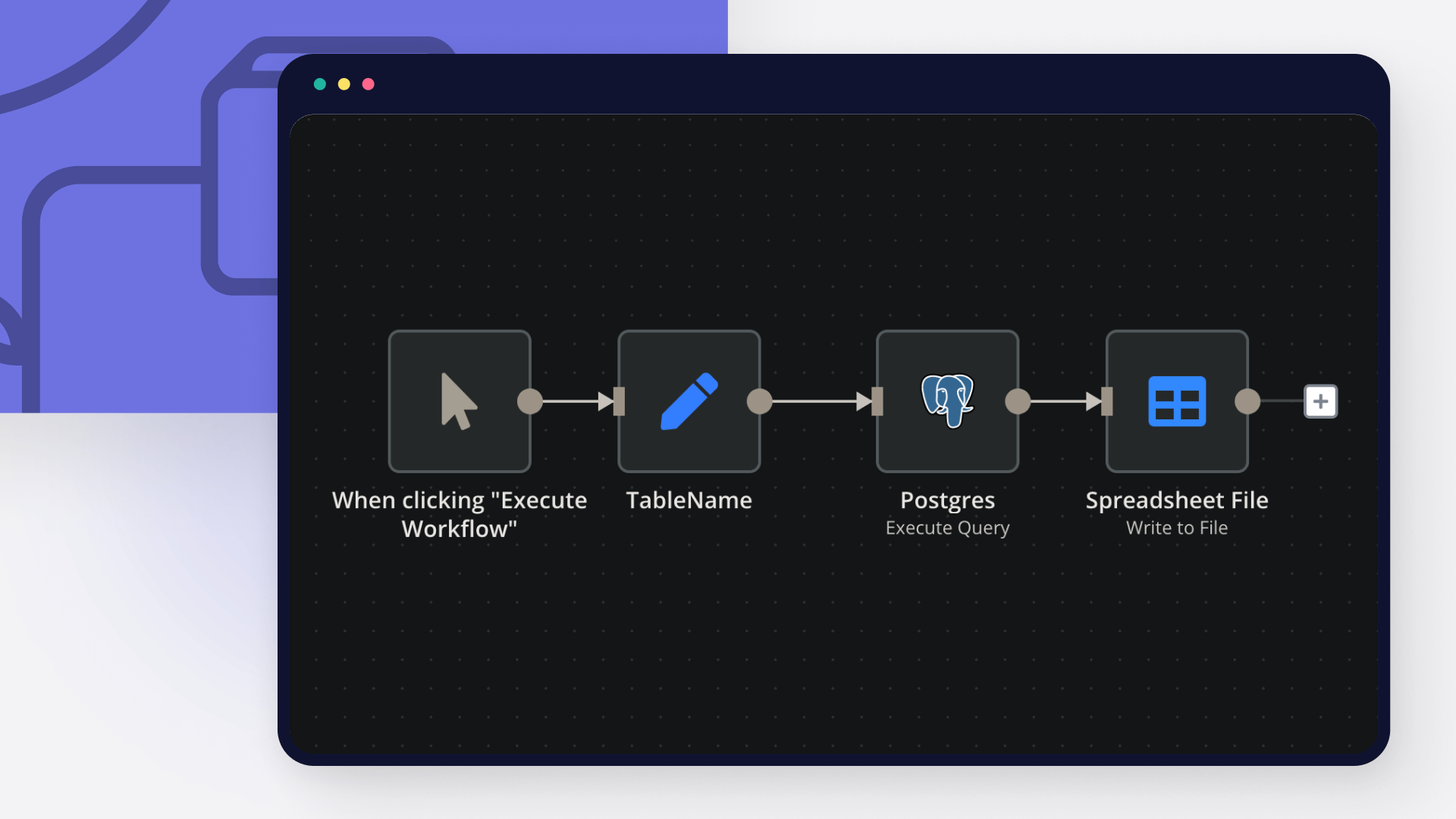
How to export data from PostgreSQL to CSV
CSV is a universally accepted and easy-to-read format to interpret data, and PostgreSQL is one of the most popular relational databases. Read on to learn how to export PostgreSQL as a CSV file using the COPY command, \copy command, and n8n.
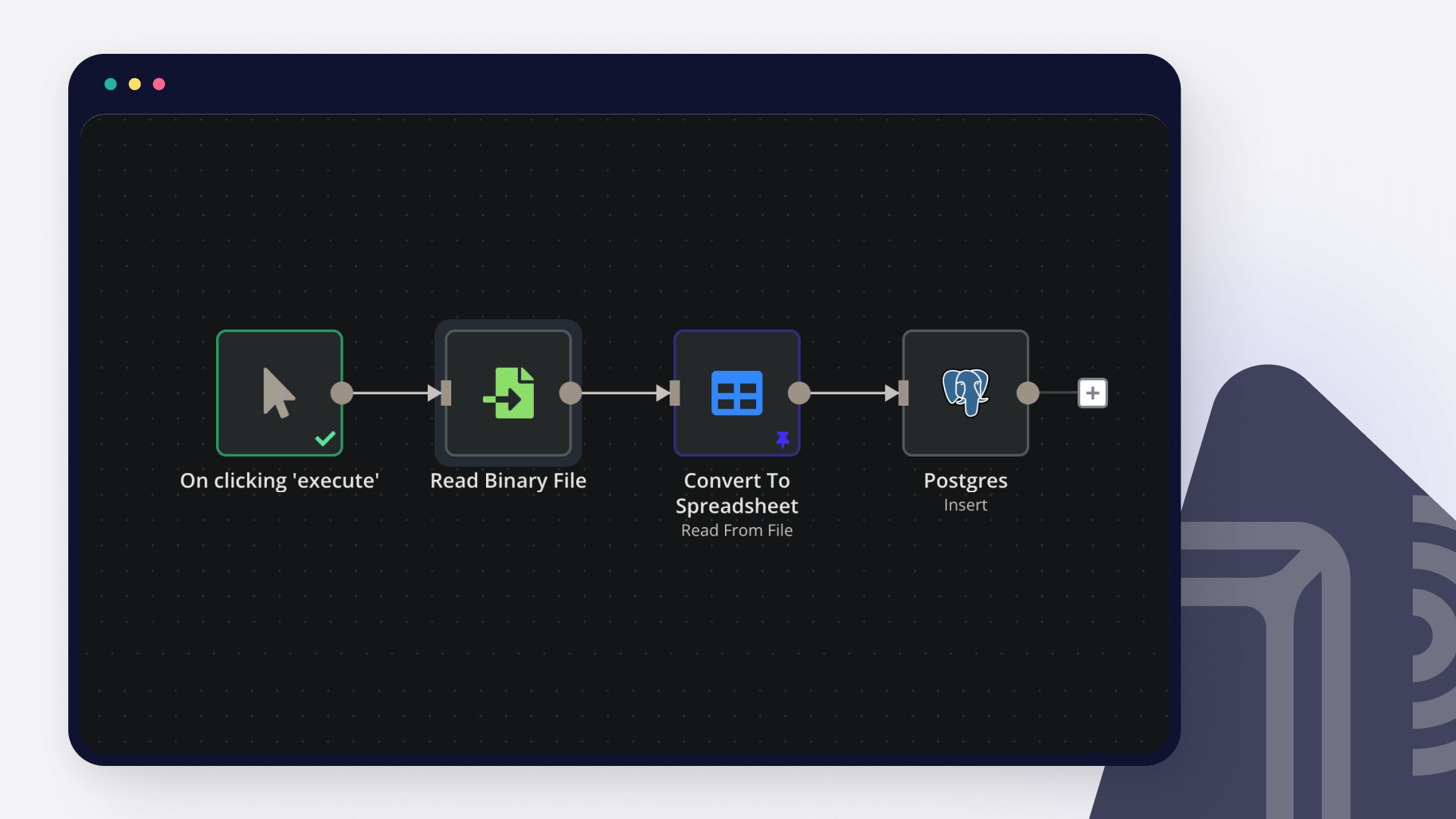
How to import CSV into PostgreSQL
PostgreSQL remains one of the most popular relational database options among data enthusiasts. Read on to learn how to import a CSV file into PostgreSQL using pgAdmin, SQL statements, and n8n.
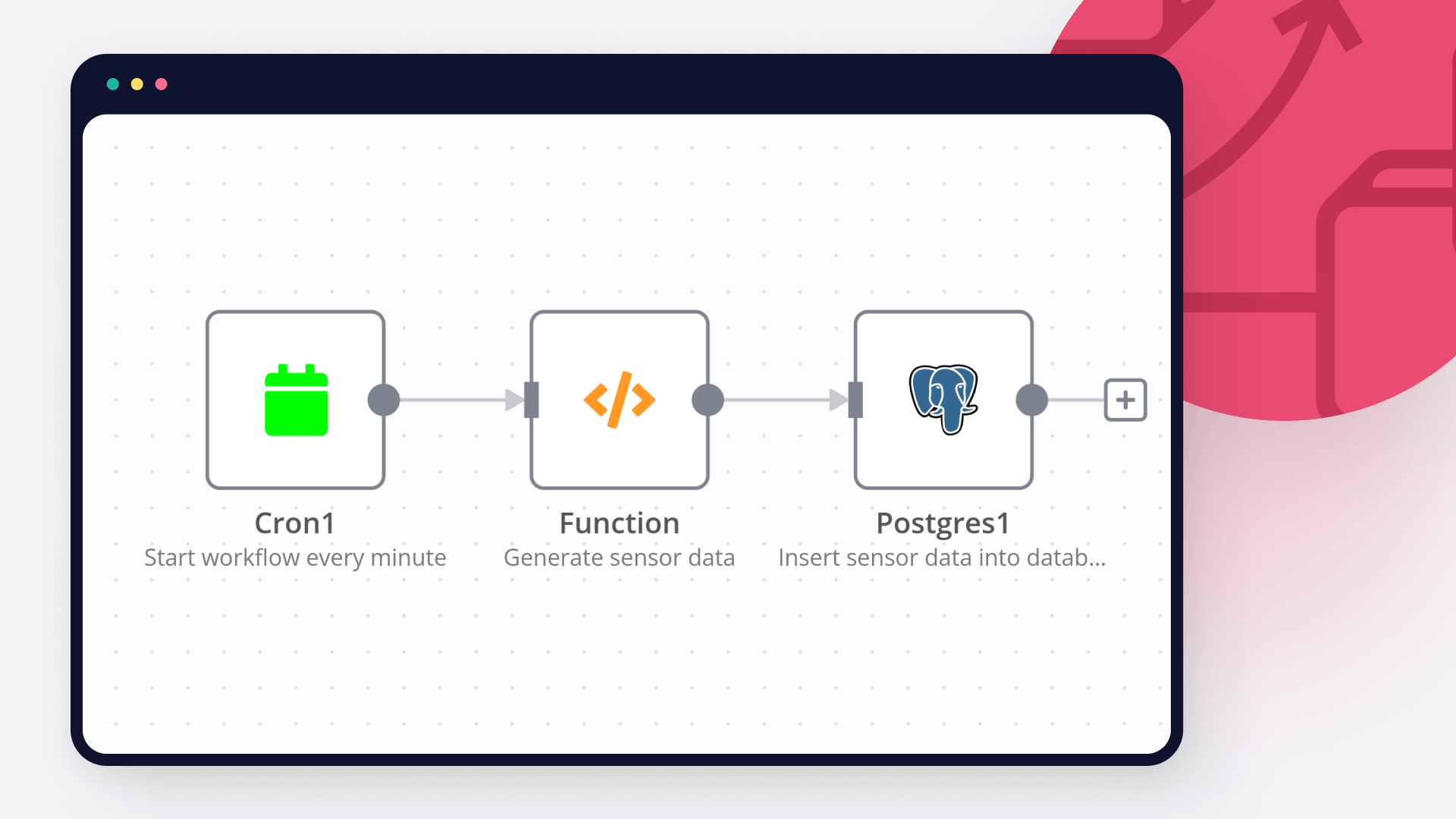
Database activity monitoring: How to automatically monitor and set alerts for a database
Learn what database activity monitoring is, why it's important, and how to automatically monitor a Postgres database containing IoT data with n8n workflows.

Automate your data processing pipeline in 9 steps
Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.
FAQs
FAQ
Can Postgres connect with Wordpress?
Can I use Postgres’s API with n8n?
Can I use Wordpress’s API with n8n?
Is n8n secure for integrating Postgres and Wordpress?
How to get started with Postgres and Wordpress integration in n8n.io?
Need help setting up your Postgres and Wordpress integration?
Discover our latest community's recommendations and join the discussions about Postgres and Wordpress integration.

Postgres node IN operator with parameters
Mikhail Savenkov
Describe the problem/error/question Postgres node is not working with IN Operator when the parameters is an Array. I suppose that’s because of the sanity checks. E.g. I have a list of some workflows that I’m returning v…

Passing an array as query parameter in Postgresql
Honza Pav
Hello, I have a follow-up question related to a topic that has been discussed but is closed: Postgres use array as a query parameters I want to pass an array into a Postgresql query as a query parameter. Ideally, I woul…

Issue with AI Agent not reading full PostgreSQL data
CrizCJK
Hello everyone, I’m running into an issue with PostgreSQL in n8n that I can’t figure out. My PostgreSQL database has about 20,000 records of sales and stock data. The problem is that my AI Agent doesn’t seem to read th…

Postgresql Insert error parsing ISO format string
Thạch Vũ Ngọc
I using Postgresql Insert node, but it error when column type is timestamp I have the input date in ISO 8601 date string format and I keep getting an error. What is the error message (if any)? Input of Insert node O…

Pass dynamic perameters to postgres_SQL node query
Shazim Ali
hi i am new to n8n basically i have build a chat bot, which is created query on the base of question, but sometime AI based queries are failed to give accurate result, so i have created sql function in vector database, t…
The world's most popular workflow automation platform for technical teams including









Why use n8n to integrate Postgres with Wordpress
Build complex workflows, really fast
