Back to Templates


Primer workflow for OpenAI models: ChatGPT, DALLE-2, Whisper
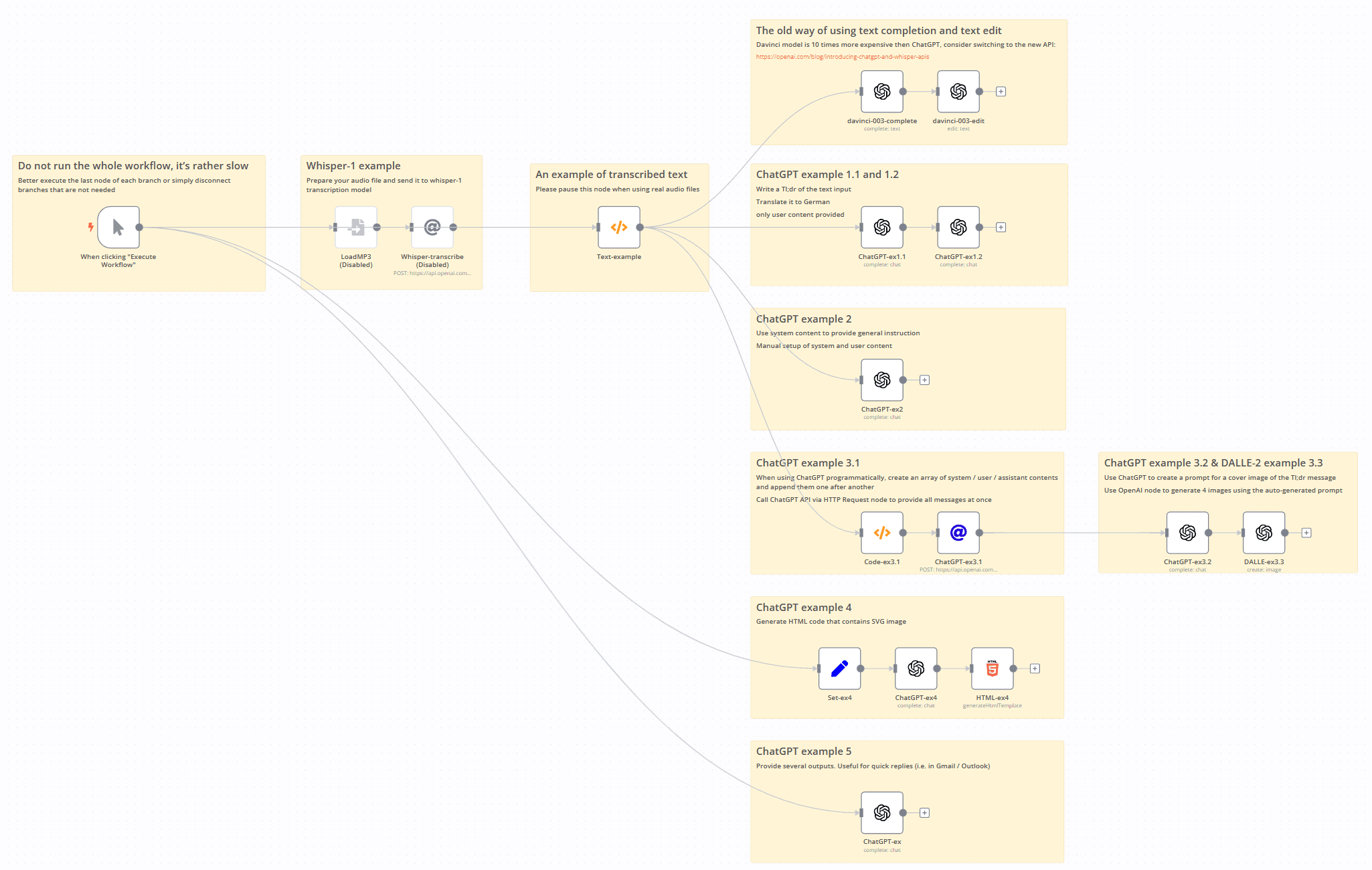
This workflow contains 5 examples on how to work with OpenAI API.
- Transcribe voice into text via Whisper model (disabled, please put your own mp3 file with voice)
- The old way of using OpenAI conversational model via text-davinci-003
- Examples 1.x. Simple ChatGPT calls. Text completion and text edit
- Example 2. Provide system and user content into ChatGPT
- Examples 3.x. Create system / user / assistanc content via Code Node. Promtp chaining technique example
- Example 4. Generate code via ChatGPT
- Example 5. Return multiple answers. Useful for providing picking the most relevant reply
IMPORTANT!
Do not run the whole workflow, it's rather slow
Better execute the last node of each branch or simply disconnect branches that are not needed