Back to Templates


Extract and Convert PDF Documents to Markdown with LlamaIndex Cloud API
Overview
This workflow automatically converts PDF documents to Markdown format using the LlamaIndex Cloud API. LlamaIndex is a powerful data framework that specializes in connecting large language models with external data sources, offering advanced document processing capabilities with high accuracy and intelligent content extraction.
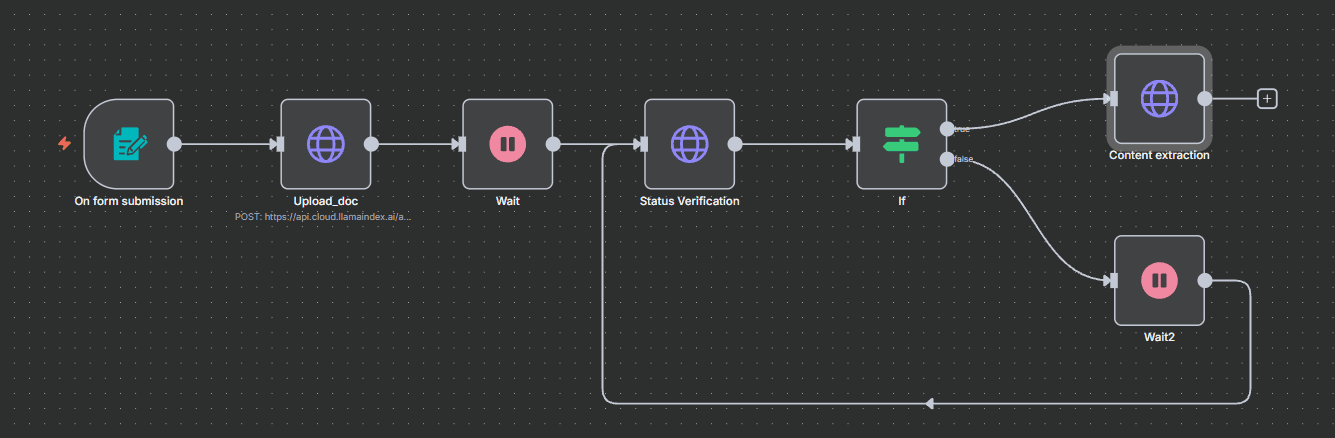
How It Works
Automatic Processing Pipeline:
- Form Submission Trigger: Workflow initiates when a user submits a document through a web form
- Document Upload: PDF files are automatically uploaded to LlamaIndex Cloud for processing
- Smart Status Monitoring: The system continuously checks processing status and adapts the workflow based on results
- Conditional Content Extraction: Upon successful processing, extracted Markdown content is retrieved for further use
Setup Instructions
Estimated Setup Time: 5-10 minutes
Prerequisites
- LlamaIndex Cloud account and API credentials
- Access to n8n instance (cloud or self-hosted)
Configuration Steps
-
Configure Form Trigger
- Set up the webhook form trigger with file upload capability
- Add required fields to capture document metadata and processing preferences
-
Setup LlamaIndex API Connection
- Obtain your API key from LlamaIndex Cloud dashboard
- Configure the HTTP Request node with your credentials and endpoint URL
- Set proper authentication headers and request parameters
-
Configure Status Verification
- Define polling intervals for status checks (recommended: 10-30 seconds)
- Set maximum retry attempts to avoid infinite loops
- Configure success/failure criteria based on API response codes
-
Setup Content Extractor
- Configure output format preferences (Markdown styling, headers, etc.)
- Set up error handling for failed extractions
- Define content storage or forwarding destinations
Use Cases
- Document Digitization: Convert legacy PDF documents to editable Markdown format
- Content Management: Prepare documents for CMS integration or static site generators
- Knowledge Base Creation: Transform PDF manuals and guides into searchable Markdown content
- Academic Research: Convert research papers and publications for analysis and citation
- Technical Documentation: Process PDF specifications and manuals for developer documentation
Key Features
- Fully automated PDF to Markdown conversion
- Intelligent content structure preservation
- Error handling and retry mechanisms
- Status monitoring with real-time feedback
- Scalable processing for batch operations
Requirements
- LlamaIndex Cloud API key
- n8n instance (v0.200.0 or higher recommended)
- Internet connectivity for API access
Support
For issues related to LlamaIndex API, consult their official documentation docs. For n8n-specific questions, refer to the n8n community forum.