Back to Templates



URL Officer - Respect robots.txt and Avoid Undesirable Sources
🎬 Overview
Version : 1.0
The URL Officer workflow automates the filtering of URLs by checking them against a database of forbidden sources and the rules defined in robots.txt files. It proactively respects robot exclusion protocols and user-defined banned sources to aid in lawful and ethical web automation. Designed primarily as a sub-workflow, it serves automation pipelines with robust URL validation to avoid undesirable or restricted sources.
✨ Features
- Dual-layer URL Filtering: Checks URLs against a manually maintained forbidden sources list and robots.txt restrictions.
- Automated robots.txt Retrieval & Update: Automatically fetches and updates robots.txt content for new or outdated sources (older than 3 days).
- AI-backed robots.txt Interpretation: Uses AI models to interpret robots.txt comments and restrictions, ensuring nuanced compliance.
- Configurable User-Agent Identification: Allows customization of User-Agent strings that are checked against robots.txt directives.
- Sub-Workflow Ready: Easily integrates as a sub-workflow for link validation in larger automation pipelines.
- Multi-Model AI Support: Supports mistral, groq, and gemini AI models for enhanced robots.txt compliance checks.
- Detailed Diagnostic Outputs: Returns comprehensive link allowance statuses and metadata for use in downstream processing.
- Database Integration: Utilizes PostgreSQL to store and manage robots.txt content and banned source lists.
👤 Who is this for?
Ideal for developers, data engineers, researchers, or businesses implementing web crawlers, scrapers, or any automation that processes URLs. This workflow helps your compliance with source restrictions and avoids content from blacklisted sites, reducing legal exposure and promoting ethical data use.
💡 What problem does this solve?
URL Officer addresses the challenge of automating URL validation by combining manual blacklist filtering with automated and AI-assisted robots.txt parsing. It prevents accidental scraping or processing from undesirable or disallowed sources, helping automate respect for webmasters' policies and legal boundaries.
🔍 What this workflow does
When given a URL, the workflow:
- Extracts the base URL.
- Checks the URL against a manually configured banned sources list (stored in database).
- Fetches robots.txt for new or stale sources (older than 3 days).
- Performs a programmatic parse and check of robots.txt directives against the URL using the specified User-Agent.
- Runs an AI model to analyze robots.txt content and confirm if the URL is allowed, taking into account any special comments or prohibitions relevant to the automation goal.
- Returns a final "allow or disallow" determination for both the URL and its base URL, along with metadata about the robots.txt fetch status and timing.
🔄 Workflow Steps
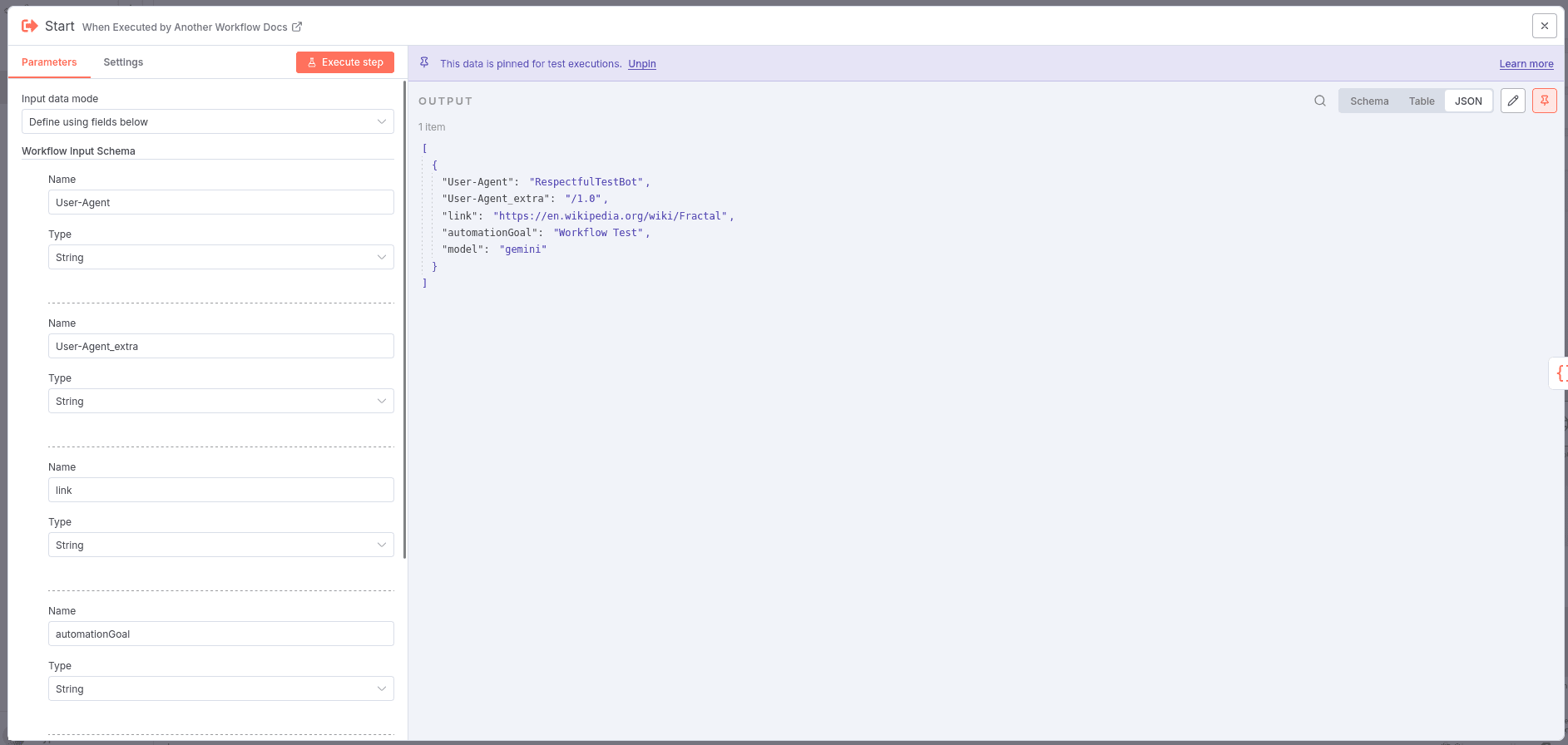
1. Input Parsing & Base URL Extraction
- Accepts workflow arguments including the URL, User-Agent information, automation goal, and AI model choice.
- Extracts and normalizes the base URL for processing.
2. Forbidden Source Check
- Queries PostgreSQL tables containing banned sources.
- Immediately rejects URLs matching forbidden sources.
3. robots.txt Handling
- Checks if robots.txt content for the source is in the database and is recent (under 3 days old).
- If missing or outdated, fetches the robots.txt file from the base URL and updates the database.
4. Code-Based robots.txt Analysis
- Parses robots.txt directives, matching the User-Agent to appropriate groups.
- Checks if the URL and base URL paths are allowed according to the parsed rules.
- Uses a conservative URL and agent matching algorithm for prefix-based allow/disallow checks.
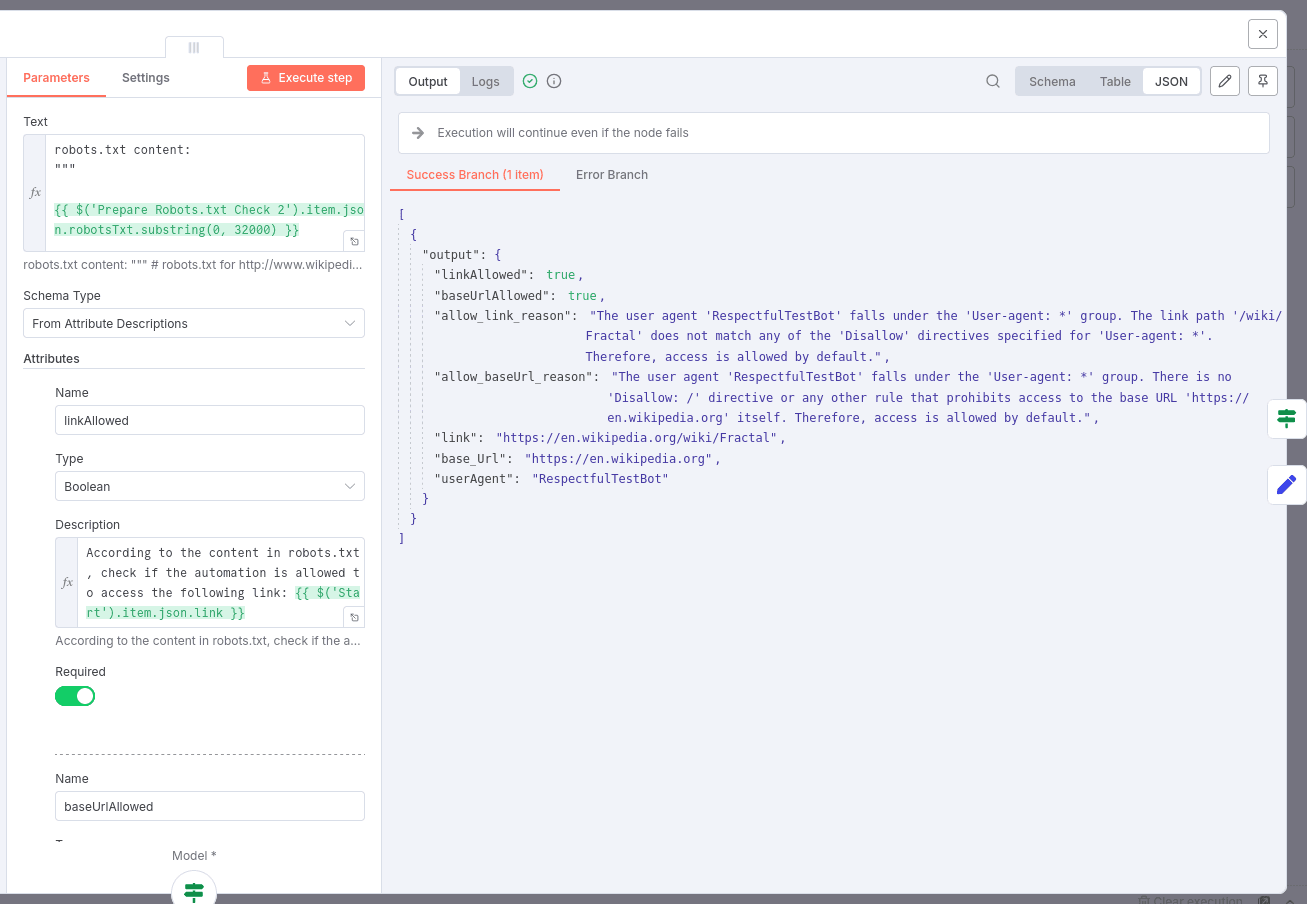
5. AI-Based robots.txt Verification
- Uses the selected AI model (mistral, groq, or gemini) to analyze robots.txt content and comments regarding allowed automation use.
- Applies AI understanding to confirm or override automated code checks based on the automation's goal.
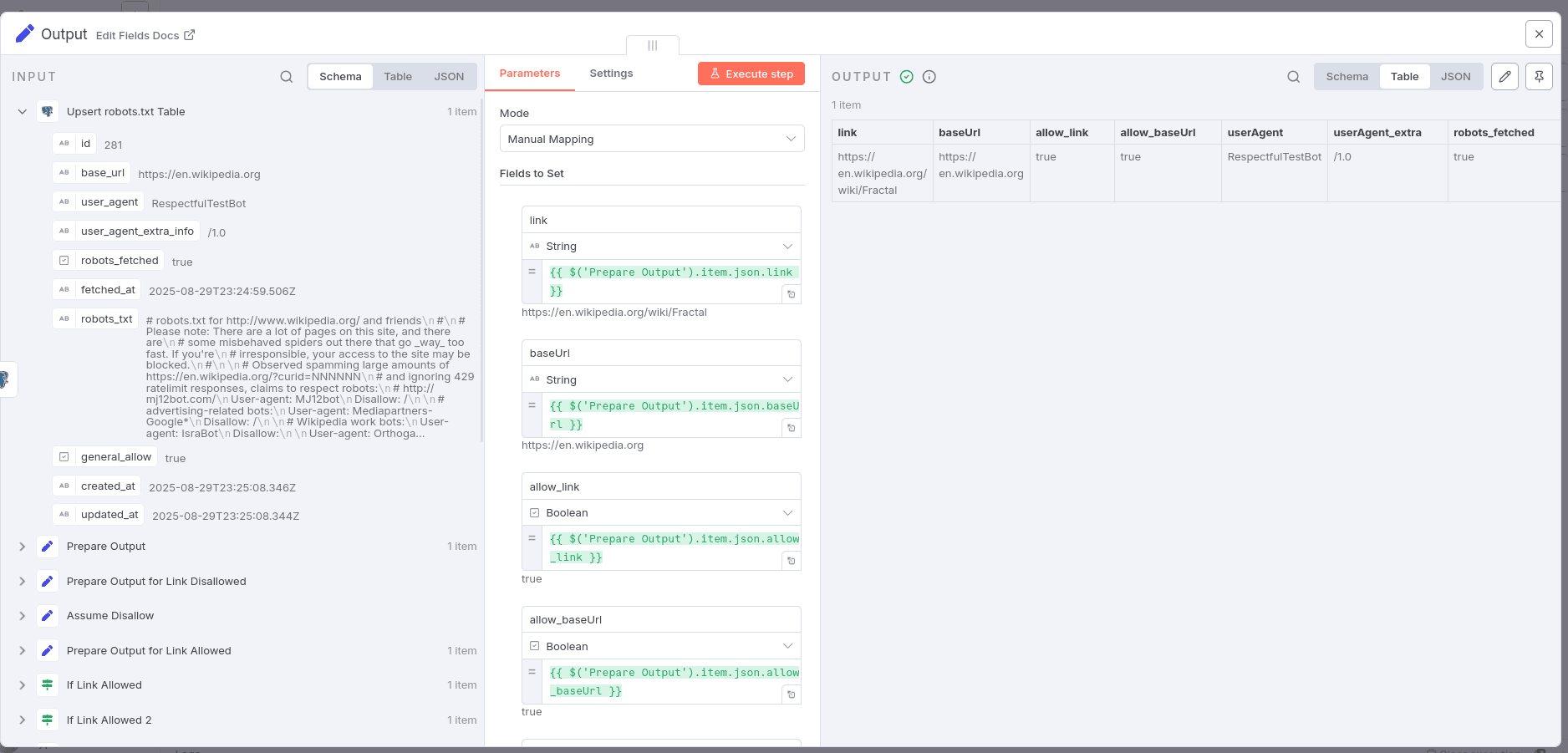
6. Output Preparation
- Produces output indicating permission statuses (
allow_linkandallow_baseUrl), original URLs, User-Agent info, fetch timestamps, and whether robots.txt was successfully retrieved. - Designed to be consumed by other workflows as a validation step.
🔀 Expected Input / Configuration
The workflow is configured primarily via workflow input arguments:
| Parameter | Description | Type |
|---|---|---|
link |
The URL to be checked. | String |
userAgent |
User-Agent string representing your automation, used for robots.txt checks. | String |
userAgent_extra |
Additional User-Agent information such as version or contact info. | String |
automationGoal |
Description of your automation’s purpose, used by the AI to verify suitability against robots.txt. | String |
model |
AI model to use for the robots.txt compliance check. Options: mistral, groq, gemini. | String |
Database Requirements
- PostgreSQL database configured with credentials accessible to the workflow.
- Two tables: one for banned sources (manually maintained) and one for robots.txt content with timestamps.
- The workflow auto-creates and manages these tables.
- Recommended to use a containerized PostgreSQL instance (Podman or Docker).
📦 Expected Output
A structured JSON object containing:
| Output Key | Description |
|---|---|
link |
The URL that was checked. |
baseUrl |
The base URL of the checked link. |
allow_link |
Boolean indicating if the link is allowed according to checks. |
allow_baseUrl |
Boolean indicating if the base URL is allowed. |
userAgent |
User-Agent string used in the check. |
userAgent_extra |
Additional User-Agent metadata. |
robots_fetched |
Boolean, true if robots.txt content was successfully fetched. |
fetched_at |
Timestamp of the last robots.txt content fetch. |
📌 Example
Example input payload:
⚙️ n8n Setup Used
- n8n version: 1.108.2
- Platform: Podman 4.3.1 on Linux
- PostgreSQL: Running in Podman 4.3.1 container
- LLM Models: mistral-small-latest, llama-3.1-8b-instant (Groq), gemini-2.5-flash
- Date: 2025-08-29
⚡ Requirements to Use / Setup
- Self-hosted or cloud n8n instance with database connectivity.
- PostgreSQL database configured and accessible by n8n.
- Setup PostgreSQL using the recommended containerized deployment or your preferred method.
- Configure database credentials inside the workflow.
- Provide API credentials for your chosen AI model (mistral, groq, gemini).
- Manually maintain the banned sources list in the database.
- Familiarity with n8n variables and sub-workflow integration is recommended.
- Internet connectivity for fetching robots.txt files.
⚠️ Notes, Assumptions & Warnings
- Database tables used by this workflow are automatically created and managed by the workflow.
- robots.txt refresh interval is set to every 3 days; this can be adjusted by modifying the workflow.
- The robots.txt parser is relatively simple and does not support wildcard (*) or end-of-string ($) rules.
- User-Agent matching is substring-based and longer string matches take precedence.
- AI analysis adds a human-like understanding of robots.txt comments and prohibitions but depends on the quality and capability of the chosen AI model.
- This workflow does NOT handle:
- Terms of Service compliance.
- Preference for official APIs over HTML scraping.
- Rate-limiting or request throttling.
- Handling paywalled or restricted content.
- De-duplication or filtering beyond the banned sources list.
- Encryption or secure storage.
- You remain responsible for ensuring your automation complies with legal, ethical, and platform-specific rules.
- The workflow is designed as a sub-workflow; integrate it into larger automation processes to validate URLs.
🛠 PostgreSQL Setup Instructions (Self-Hosted Route)
Available inside the Workflow Notes, alongside podman commands.
ℹ️ About Us
This workflow was developed by the Hybroht team. Our goal is to create tools that harness the possibilities of technology and more. We aim to continuously improve and expand functionalities based on community feedback and evolving use cases.
For questions, support, or feedback, please contact us at: [email protected]
⚖️ Warranty & Legal Notice
This workflow is provided "as-is" without warranties of any kind. By using this workflow, you agree that you are responsible for complying with all applicable laws, regulations, and terms of service related to your data sources and automations. Please review all relevant legal terms and use this workflow responsibly.
Hybroht disclaims any liability arising from use or misuse of this workflow. This tool assists with robots.txt compliance but is not a substitute for full legal or compliance advice.
You can view the full license terms here. Please review them before making your purchase.
By purchasing this product, you agree to these terms.