Back to Templates



⚠️ IMPORTANT: This template requires self-hosted n8n hosting due to the use of community nodes (MCP tools). It will not work on n8n Cloud. Make sure you have access to a self-hosted n8n instance before using this template.
Overview
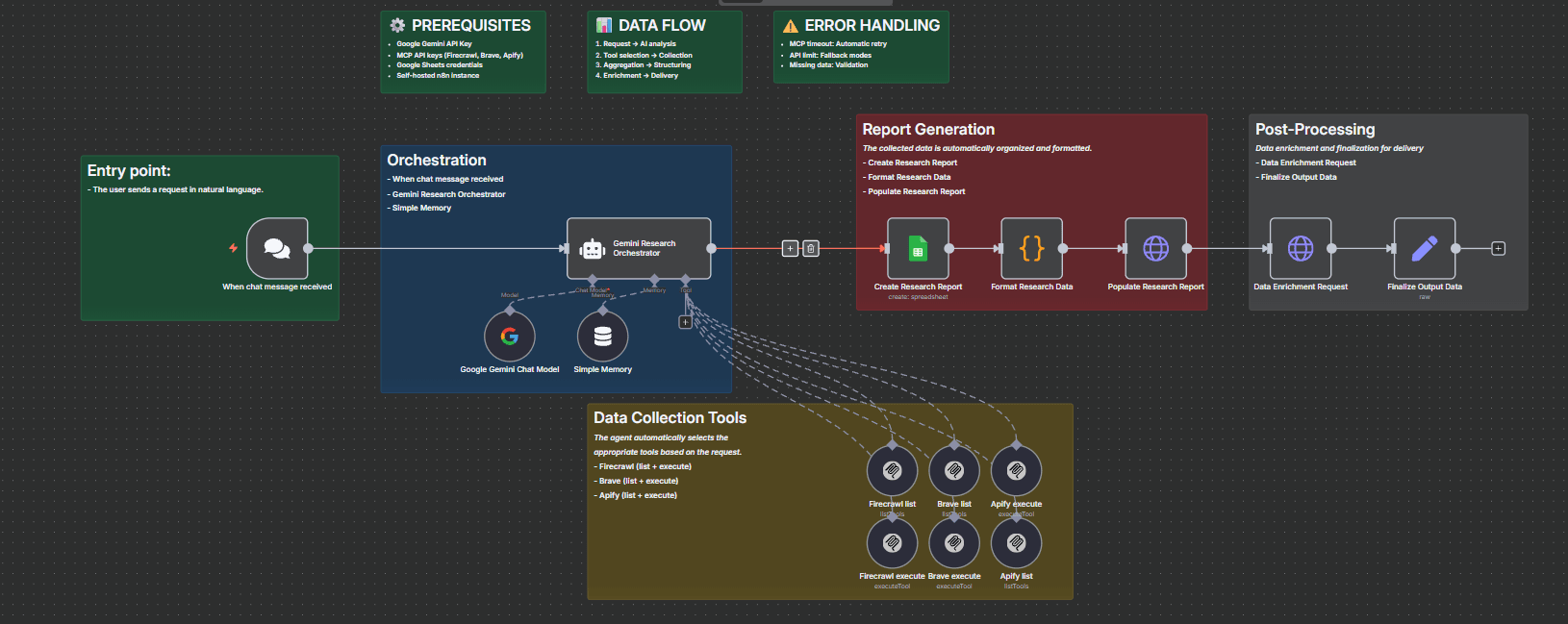
This workflow automation allows a Google Gemini-powered AI Agent to orchestrate multi-source web intelligence using MCP (Model Context Protocol) tools such as Firecrawl, Brave Search, and Apify.
The system allows users to interact with the agent in natural language, which then leverages various external data collection tools, processes the results, and automatically organizes them into structured spreadsheets.
With built-in memory, flexible tool execution, and conversational capabilities, this workflow acts as a multi-agent research assistant, capable of retrieving, synthesizing, and delivering actionable insights in real time.
How the system works
AI Agent + MCP Pipeline
-
User Interaction
A chat message is received and forwarded to the AI Agent. -
AI Orchestration
The agent, powered by Google Gemini, decides which MCP tools to invoke based on the query.- Firecrawl-MCP: Recursive web crawling and content extraction.
- Brave-MCP: Real-time web search with structured results.
- Apify-MCP: Automation of web scraping tasks with scalable execution.
-
Memory Management
A memory module stores context across conversations, ensuring multi-turn reasoning and task continuity. -
Spreadsheet automation
Results are structured in a new, automatically created Google Spreadsheet, enriched with formatting and additional metadata. -
Data processing
The workflow generates the spreadsheet content, updates the sheet, and improves results via HTTP requests and field edits. -
Delivery of results
Users receive a structured and contextualized dataset ready for review, analysis, or integration into other systems.
Configuration instructions
Estimated setup time: 45 minutes
Prerequisites
- Self-hosted n8n instance (v0.200.0 or higher recommended)
- Google Gemini API key
- MCP-compatible nodes (Firecrawl, Brave, Apify) configured
- Google Sheets credentials for spreadsheet automation
Detailed configuration steps
Step 1: Configuring the AI Agent
- AI Agent node:
- Select Google Gemini as the LLM model
- Configure your Google Gemini API key in the n8n credentials
- Set the system prompt to guide the agent's behavior
- Connect the Simple Memory node to enable context tracking
Step 2: Integrating MCP Tools
-
Firecrawl-MCP Configuration:
- Install the
@n8n/n8n-nodes-firecrawl-mcppackage - Configure your Firecrawl API key
- Set crawling parameters (depth, CSS selectors)
- Install the
-
Brave-MCP configuration:
- Install the
@n8n/n8n-nodes-brave-mcppackage - Add your Brave Search API key
- Configure search filters (region, language, SafeSearch)
- Install the
-
Apify-MCP configuration:
- Install the
@n8n/n8n-nodes-apify-mcppackage - Configure your Apify credentials
- Select the appropriate actors for your use cases
- Install the
Step 3: Spreadsheet automation
-
“Create Spreadsheet” node:
- Configure Google Sheets authentication (OAuth2 or Service Account)
- Set the file name with dynamic timestamps
- Specify the destination folder in Google Drive
-
“Generate Spreadsheet Content” node:
- Transform the agent's outputs into tabular format
- Define the columns: URL, Title, Description, Source, Timestamp
- Configure data formatting (dates, links, metadata)
-
“Update Spreadsheet” node:
- Insert the data into the created sheet
- Apply automatic formatting (headers, colors, column widths)
- Add summary formulas if necessary
Step 4: Post-processing and delivery
-
“Data Enrichment Request” node (formerly “HTTP Request1”):
- Configure optional API calls to enrich the data
- Add additional metadata (geolocation, sentiment, categorization)
- Manage errors and timeouts
-
“Edit Fields” node:
- Refine the final dataset (metadata, tags, filters)
- Clean and normalize the data
- Prepare the final response for the user
Structure of generated Google Sheets
Default columns
| Column | Description | Type |
|---|---|---|
| URL | Data source URL | Hyperlink |
| Title | Page/resource title | Text |
| Description | Description or content excerpt | Long text |
| Source | MCP tool used (Brave/Firecrawl/Apify) | Text |
| Timestamp | Date/time of collection | Date/Time |
| Metadata | Additional data (JSON) | Text |
Automatic formatting
- Headings: Bold font, colored background
- URLs: Formatted as clickable links
- Dates: Standardized ISO 8601 format
- Columns: Width automatically adjusted to content
Use cases
Business and enterprise
- Competitive analysis combining search, crawling, and structured scraping
- Market trend research with multi-source aggregation
- Automated reporting pipelines for business intelligence
Research and academia
- Literature discovery across multiple sources
- Data collection for research projects
- Automated bibliographic extraction from online sources
Engineering and development
- Discovery of APIs and documentation
- Aggregation of product information from multiple platforms
- Scalable structured scraping for datasets
Personal productivity
- Automated creation of newsletters or knowledge hubs
- Personal research assistant compiling spreadsheets from various online data
Key features
Multi-source intelligence
- Firecrawl for deep crawling
- Brave for real-time search
- Apify for structured web scraping
AI-driven orchestration
- Google Gemini for reasoning and tool selection
- Memory for multi-turn interactions
- Context-based adaptive workflows
Structured data output
- Automatic spreadsheet creation
- Data enrichment and formatting
- Ready-to-use datasets for reporting
Performance and scalability
- Handles multiple simultaneous tool calls
- Scalable web data extraction
- Real-time aggregation from multiple MCPs
Security and privacy
- Secure authentication based on API keys
- Data managed in Google Sheets / n8n
- Configurable retention and deletion policies
Technical architecture
Workflow
User query → AI agent (Gemini) → MCP tools (Firecrawl / Brave / Apify) → Aggregated results → Spreadsheet creation → Data processing → Results delivery
Supported data types
- Text and metadata from crawled web pages
- Search results from Brave queries
- Structured data from Apify scrapers
- Tabular reports via Google Sheets
Integration options
Chat interfaces
- Web widget for conversational queries
- Slack/Teams chatbot integration
- REST API access points
Data sources
- Websites (via Firecrawl/Apify)
- Search engines (via Brave)
- APIs (via HTTP Request enrichment)
Performance specifications
- Query response: < 5 seconds (search tasks)
- Crawl capacity: Thousands of pages per run
- Spreadsheet automation: Real-time creation and updates
- Accuracy: > 90% when using combined sources
Advanced configuration options
Customization
- Set custom prompts for the AI Agent
- Adjust the spreadsheet schema for reporting needs
- Configure retries for failed tool runs
Analytics and monitoring
- Track tool usage and costs
- Monitor crawl and search success rates
- Log queries and outputs for auditing
Troubleshooting and support
- Timeouts: Manually re-run failed MCP executions
- Data gaps: Validate Firecrawl/Apify selectors
- Spreadsheet errors: Check Google Sheets API quotas